
Cómo entrenar LoRA NSFW (actualizado con FLUX)
g
By gerogero
Updated: March 13, 2026
Modelos utilizados para el entrenamiento
Para SD 1.5 fotos realistas:
- Entrenamiento: Realistic Vision 5.1
Este se agregó en las fusiones de mayo y también es parte de una fusión. Funciona bien con casi todos los demás modelos realistas. La v6 por alguna razón no funciona bien de la misma manera. - Generación: Realistic Vision 5.1, y un img2img con un denoise de 0.1 usando PicX Real 1.0. RV solo hace el trabajo, pero me gustó esta combinación.
Para SD 1.5 Anime:
- Entrenamiento: AnyLora
Este es un clásico para el entrenamiento. - Generación: Azure Anime v5
Para SDXL en general (incluye Pony e Illustrious aquí):
- Entrenamiento: Modelo base SDXL
- Generación: Dreamshaper XL Turbo. Uso 7 pasos, y luego hago un img2img con el mismo prompt pero una nueva semilla, ¡entonces el resultado es agradable!
Para FLUX en general:
- Modelo: flux1-Dev-Fp8.safetensors (archivo de 11.1 GB)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 Encoder: t5xxl_fp8_e4m3fn.safetensors
- Se necesita 16Gb de Vram. Pero puedes probar este otro artículo aquí.
Herramientas que uso
- Para el entrenamiento necesitarás instalar: Kohya_ss
Pero a veces solo ejecuto un script que hice para acelerar el proceso, llama a los scripts de Kohya con todos los parámetros. Hablaré de eso al final.
La rama sd3-flux.1 es necesaria para Flux. - Generación: InvokeAI
Lo siento gente, tengo Automatic1111 y ComfyUI aquí, pero amo InvokeAI. - Visor de metadatos Lora: https://civitai.com/models/249721
Preparación del conjunto de datos
Esta es la parte más importante. Tienes que recopilar imágenes de la persona, objeto o lo que quieras entrenar.
Hay algunas cosas a considerar
- Evita resoluciones bajas o imágenes pixeladas. No recomiendo hacer upscaling.
- Evita imágenes demasiado diferentes entre sí. Normalmente me apego a retratos.
- Evita imágenes con demasiado maquillaje, muchos aretes y collares, poses extrañas.
- MANOS. Evita imágenes donde las manos aparezcan demasiado en posiciones extrañas.
- Corto una por una para asegurarme de que incluyan solo el sujeto a entrenar, eliminando logotipos, otras personas, espacios desperdiciados, etc.
Déjame mostrarte el conjunto de datos que obtuve para Silvio Santos lora:

Puedes ver que todos son retratos. Diferentes fondos y colores de ropa son un MUST. Caras mirando hacia diferentes lados también.
Nota sobre la simetría
Verifica si todos los lados derecho e izquierdo de la persona son consistentes. Esto puede no ser el caso con selfies que generalmente están invertidas.
El rostro humano no es simétrico, entonces si tienes una orientación lateral mixta durante tu entrenamiento, el resultado puede ser así:

¡Por favor, revisa la orientación de todo tu conjunto de datos!
Si las imágenes de vista previa después de un tiempo comienzan a ser todas iguales, esta puede ser la razón, ya que SD intentará aprender ambos lados y la diferencia en simetría puede causar que la pérdida sea un poco más alta en algunas imágenes invertidas, luego el aprendizaje se quedará atascado en algunas pocas imágenes.
Número de imágenes
- 5 a 10: Tu Lora no tendrá muchas variaciones, pero puede funcionar.
- 11 a 20: Buen lugar. Puede generar un buen lora.
- 21 a 50: ¡Este amplio rango es lo que queremos!
- 50 a 100: Demasiado, pero funciona cuando quieres agregar retratos Y cuerpo completo mezclados.
- > 100: Pérdida de trabajo.
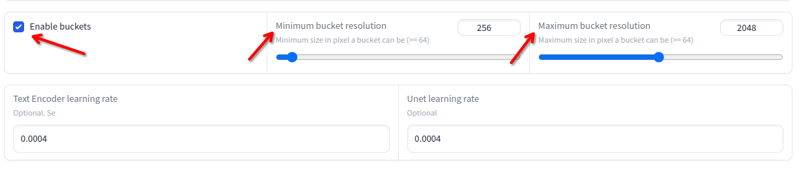
Resolución
La resolución puede variar de 256x a 2048x. Evita imágenes por debajo o por encima de estos valores. No necesitas redimensionar si están dentro de estos valores, ya que el entrenamiento lo hará automáticamente en buckets:
La estructura de carpetas:
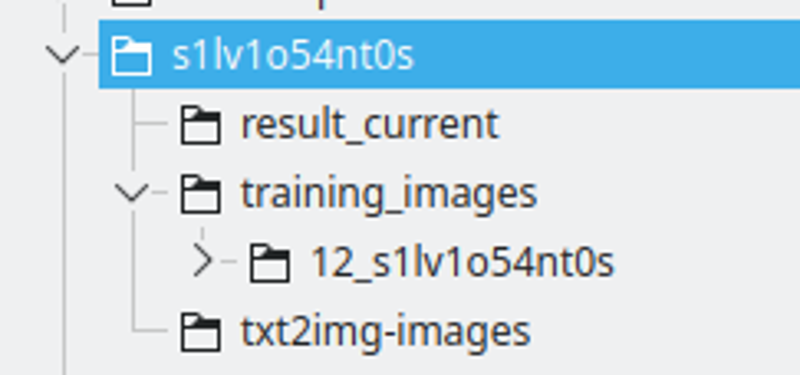
Creo una carpeta con el nombre de la cadena LoRA. Nombré la cadena reemplazando algunas letras con números, para asegurarme de que sea un token único entre muchos modelos.
El resultado_actual será el lugar donde Kohya guardará los resultados.
Las imágenes de entrenamiento tendrán el directorio que contiene las imágenes de entrenamiento. La convención de nombres es: 400 / número de imágenes, un guion bajo y la cadena lora. Este será el número de repeticiones que Kohya hará. Encuentro que este número es un buen lugar para tener un buen intervalo entre épocas.
txt2img-images es donde almaceno imágenes generadas usando la LoRA – Opcional.
Subtitulación
Este es el proceso donde describirás qué es cada imagen, luego SD sabrá cómo usar el modelo existente para construir las imágenes de entrenamiento a partir del ruido.
En Kohya, en la pestaña de utilidades, tenemos subtitulación Blip. Uso esto con estas configuraciones:
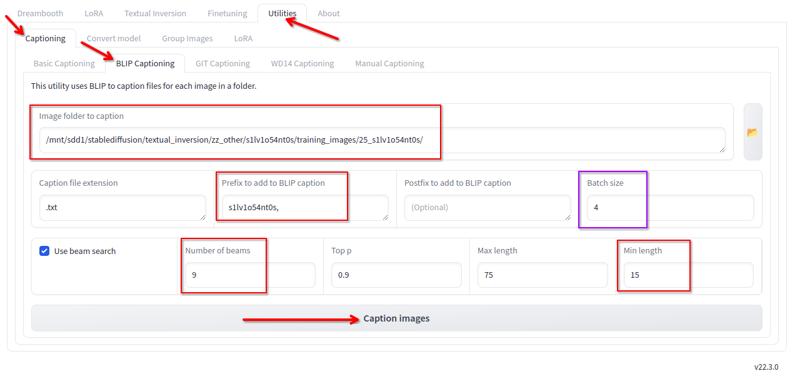
Cambio lo siguiente:
- Carpeta donde están las imágenes.
- El prefijo es el nombre de la lora y una coma.
- Número de beams 9.
- Longitud mínima 15.
- Tamaño de lote 4.
- Todos los demás valores los mantengo por defecto.
Haz clic en subtitular y, después de un tiempo, generará los subtítulos:
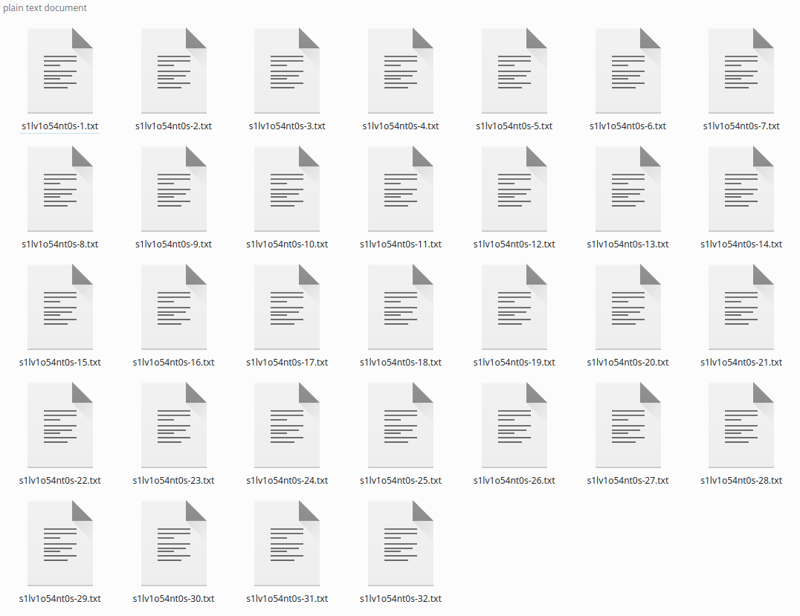
Si tienes pocas imágenes, puedes corregir los subtítulos, ya que Blip AMA agregar frases como “sosteniendo un control remoto” o “Con un micrófono en la mano” que no son ciertas. Simplemente ignoro y ha estado funcionando así, ya que la subtitulación general es buena.
*Puedes decir que esta subtitulación “básica” no es buena para Flux, que una mejor subtitulación usando LLM es mejor, pero ha estado funcionando bien para mí.
Carpeta de regularización
En el pasado, para las primeras loras que publiqué, usé una carpeta de regularización con más de 4K imágenes de mujeres. Dejé de usarla ya que solo se requiere cuando tu conjunto de datos no está subtitulado y es más variado.
Usarla duplicará el tiempo y los pasos requeridos.
No la uses.
Ejecutando el entrenamiento
Aquí ejecutaremos el entrenamiento. Para SD1.5 estas configuraciones requieren 8GB de Vram, SDXL requiere 10GB de Vram, Flux requiere 16GB de Vram.
Instalar Kohya está fuera del alcance de esta guía.
Configuraciones de Kohya
Configuraciones de SD1.5: https://jsonformatter.org/a3213d
Configuraciones de SDXL: https://jsonformatter.org/66e5c8
Configuraciones de FLUX: https://jsonformatter.org/45c1fc
* Háganme saber si los enlaces expiran
* Para FLUX, estoy limitando el entrenamiento a 1800 pasos (ya en el archivo de configuración anterior) pero alrededor de 1200 pasos la LoRA ya es buena.
* También para FLUX, mis configuraciones anteriores no estaban convergiendo el entrenamiento para ANIMES y CARICATURAS. Así que, puede que tengas que aumentar el –learning_rate=0.0004 –unet_lr=0.0004 a 0.001 o 0.002. Con eso el entrenamiento se vuelve bueno en menos pasos, pero puede sobreajustarse más fácilmente.
Simplemente carga estos archivos en la pestaña LORA — NO EN LA PESTAÑA DREAMBOOT — haz clic en archivo de configuración y cárgalo.
Configuraciones que DEBES cambiar:
Sección de Modelo y Carpetas:
- Carpeta de imágenes – la carpeta de training_images que creamos antes. NO la carpeta con el número, la carpeta principal.
- Carpeta de salida – la carpeta result_current que creamos antes.
- Nombre de salida – el nombre de la cadena de la lora.
Pestaña de Parámetros > Avanzado > Muestras:
- Cambia el prompt. Debe ser simple, se usará para generar las imágenes de muestra. Mantenlo simple.
Pestaña de Parámetros > Básico:
- Puedes cambiar el número de épocas, pero yo mantendría 6 para empezar.
Busca en internet qué significa cada campo, está fuera del alcance por ahora explicarlos todos, pero puedes leer aquí: Parámetros de entrenamiento de LoRA
Utilización de hardware
La mayoría de las configuraciones cambian los requisitos de hardware.
Estas son las que funcionaron para mí, usando una RTX2060 super con 12GB de Vram — Para FLUX actualicé a una RTX 4060 TI 16GB de Vram.
Por ejemplo, mi RTX2060 no soporta bf16 como las 3060s, entonces uso fp16. Esto me ahorraría memoria, pero así es y con 12G ha funcionado.
Después de cambiar todo eso, haz clic en “Iniciar entrenamiento“. Verás esto en la consola:
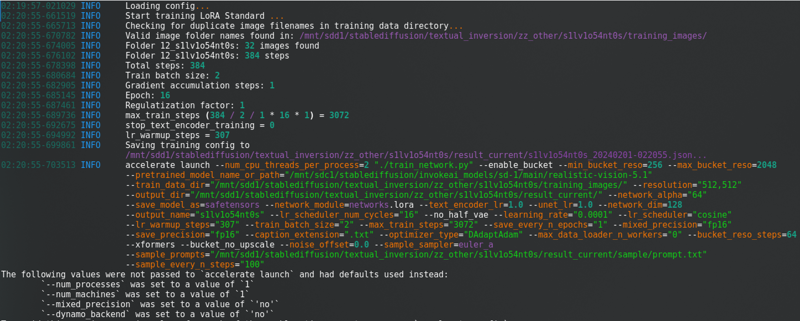
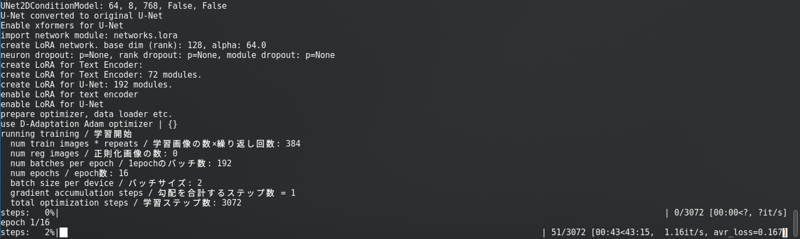
Con una barra de progreso muy larga.
SD1.5: No almaceno latentes en el disco. Es más rápido, pero usa casi la misma Vram que SDXL.
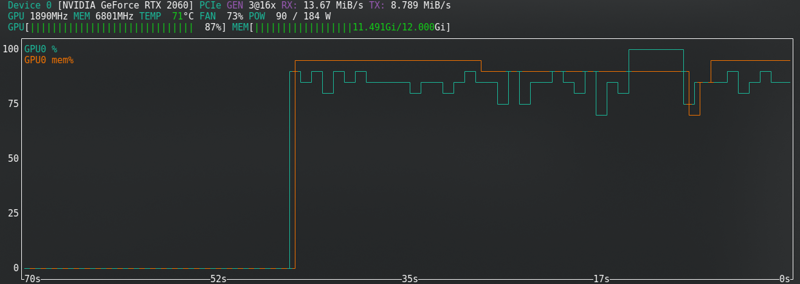

SDXL:
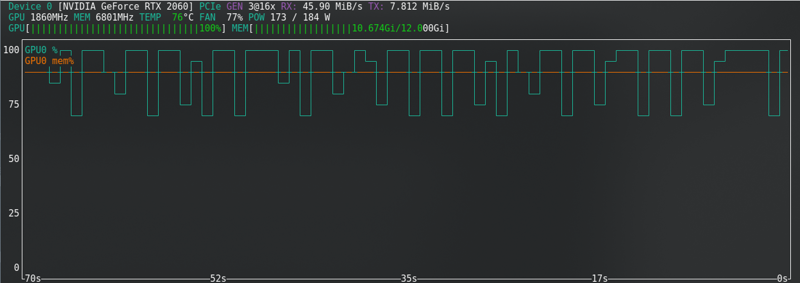

FLUX: ¡Cerca del límite incluso con la nueva tarjeta!!!!!
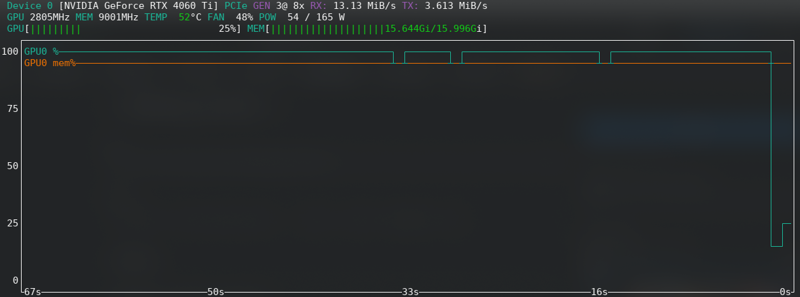
Error de falta de memoria
Si recibes errores de falta de memoria de CUDA, entonces estás en el límite. Habilita el almacenamiento en caché de latentes en el disco, cambia de fp16 a bf16 si tu hardware lo soporta, reduce el tamaño del lote de 2 a 1.
Para Flux, puedes habilitar “Modo dividido”. Esto reduce mucho la VRAM, pero casi duplica el tiempo de entrenamiento.
Otras opciones son: Cerrar todos los programas, desconectar tu segundo monitor, bajar la resolución de pantalla, si estás en Linux cambiar temporalmente a un entorno de escritorio más ligero, una vez que inicies el entrenamiento cierra el navegador y verifica el estado solo con el símbolo del sistema abierto.
Si no puedes resolverlo, busca en internet. Si aún obtienes errores, entonces rinde y entrena en CivitAI.
Vista previa del entrenamiento
Cada 100 pasos (puedes cambiarlo) el entrenamiento creará una imagen de muestra en la carpeta results_current/sample, luego puedes tener una idea si está funcionando o no.
Los resultados mejorarán con el tiempo a medida que esté aprendiendo.

Resultados del entrenamiento
Cuando termine, el directorio se verá así:
Puedes verificar por las imágenes de muestra si está sobreentrenado o subentrenado. Lo verás al ejecutar la LoRA también.
Sobreentrenado
Si el modelo está sobreentrenado, las imágenes serán “pixeladas hechas de arcilla”… No sé cómo describirlo. Las imágenes de vista previa comenzarán a distorsionarse.
Mira con tus ojos, una imagen generada:

A veces no obtiene este mal resultado, pero la cara DEJA de parecerse a la persona entrenada hasta que se deforma en épocas posteriores.

La solución es simple: Solo prueba épocas anteriores y ve la más reciente que funcione bien. Basado en la imagen de muestra, puedes encontrar fácilmente la buena y encontrar el archivo LoRA generado alrededor del mismo tiempo.
¡Es DIFÍCIL ELEGIR UNA!!! Pero debe hacerse. Prueba lo más que puedas.
Subentrenado
Si está subentrenado (El rostro del retrato no se parece a la persona y parece una mezcla de persona genérica del modelo SD, o el objeto no tiene los detalles deseados aún) puedes reanudar el entrenamiento.

En esta imagen de ejemplo ves que faltan detalles, como el micrófono fusionándose con la corbata.
La diferencia con el sobreentrenamiento es la falta de detalle.
Si cerraste Kohya, no hay problema, solo carga el json que crea en el directorio de resultados y todas las configuraciones utilizadas se cargarán.
En Parámetros > Básico, tienes el campo Pesos de red LoRA donde puedes agregar cualquier lora que quieras seguir entrenando.
Renombra la última que obtuviste a cualquier otro nombre, copia su ubicación a este campo, cambia las épocas a 2 o 3 (depende de cuánto necesites seguir entrenando) y haz clic en iniciar entrenamiento de nuevo. Esto reanudará el entrenamiento.
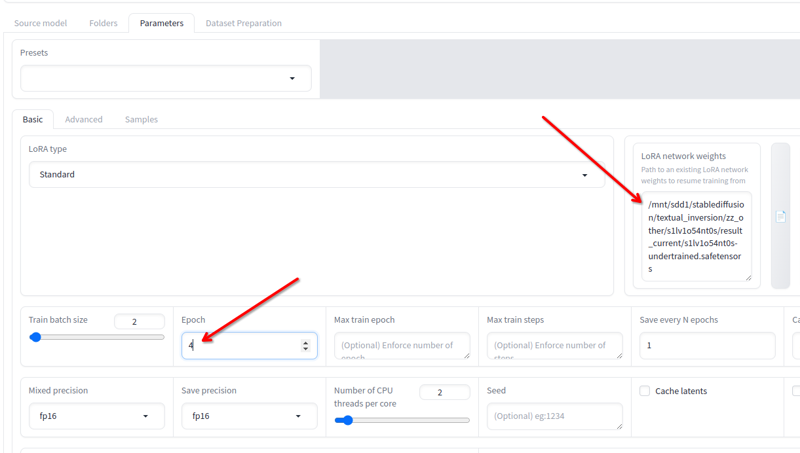
Puedes hacer eso hasta que esté bien!
¡Terminado!
Renombra la última época de lora que quieras (o mantén si el resultado final es bueno) y úsala.
Este es el ejemplo de SD1.5:

Este es el ejemplo de Flux:






