
วิธีฝึกสอน NSFW LoRA (อัปเดตสำหรับ FLUX)
g
By gerogero
Updated: March 13, 2026
โมเดล ที่ใช้ในการฝึกอบรม
สำหรับ SD 1.5 ภาพถ่ายที่สมจริง:
- การฝึกอบรม: Realistic Vision 5.1
โมเดลนี้ถูกเพิ่มในช่วงการรวมกันและยังเป็นส่วนหนึ่งของการรวมกัน ซึ่งทำงานได้ดีเกือบกับโมเดลที่สมจริงอื่นๆ ทั้งหมด แต่ v6 ด้วยเหตุผลบางอย่างทำงานได้ไม่ดีเหมือนกัน. - การสร้าง: Realistic Vision 5.1 และ img2img ด้วยการลดเสียงรบกวนที่ 0.1 โดยใช้ PicX Real 1.0. RV เพียงอย่างเดียวทำงานได้ดี แต่ฉันชอบการรวมกันนี้.
สำหรับ SD 1.5 อนิเมะ:
- การฝึกอบรม: AnyLora
โมเดลนี้เป็นคลาสสิกสำหรับการฝึกอบรม. - การสร้าง: Azure Anime v5
สำหรับ SDXL โดยรวม (รวม Pony และ Illustrious ที่นี่):
- การฝึกอบรม: SDXL Base model
- การสร้าง: Dreamshaper XL Turbo. ฉันใช้ 7 ขั้นตอน จากนั้นทำ img2img ด้วย prompt เดิมแต่ใช้ seed ใหม่ ผลลัพธ์ออกมาดีมาก!
สำหรับ FLUX โดยรวม:
- โมเดล: flux1-Dev-Fp8.safetensors (ไฟล์ขนาด 11.1 GB)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 Encoder: t5xxl_fp8_e4m3fn.safetensors
- ต้องการ Vram 16Gb. แต่คุณสามารถลองบทความอื่นๆ ที่นี่.
เครื่องมือ ที่ฉันใช้
- สำหรับการฝึกอบรมคุณต้องติดตั้ง: Kohya_ss
แต่บางครั้งฉันก็แค่รันสคริปต์ที่ฉันทำขึ้นเพื่อเร่งกระบวนการ มันเรียกสคริปต์ Kohya พร้อมกับพารามิเตอร์ทั้งหมด ฉันจะพูดถึงมันในตอนท้าย.
สาขาsd3-flux.1จำเป็นสำหรับ Flux. - การสร้าง: InvokeAI
ขอโทษทุกคน ฉันมี Automatic1111 และ ComfyUI ที่นี่ แต่ฉันชอบ InvokeAI. - Lora Metadata Viewer: https://civitai.com/models/249721
การเตรียมชุดข้อมูล
นี่คือส่วนที่สำคัญที่สุด คุณต้องรวบรวมภาพจากบุคคล วัตถุ หรืออะไรก็ตามที่คุณต้องการฝึกอบรม.
มีบางสิ่งที่ต้องพิจารณา
- หลีกเลี่ยงภาพที่มีความละเอียดต่ำหรือภาพที่มีพิกเซล ฉันไม่แนะนำให้ขยายขนาด.
- หลีกเลี่ยงภาพที่แตกต่างกันมากเกินไป ฉันมักจะยึดติดกับภาพบุคคล.
- หลีกเลี่ยงภาพที่มีการแต่งหน้ามากเกินไป มีต่างหูและสร้อยคอมากมาย ท่าทางแปลกๆ.
- มือ. หลีกเลี่ยงภาพที่มือปรากฏอยู่ในตำแหน่งแปลกๆ มากเกินไป.
- ฉันจะตัดภาพทีละภาพเพื่อให้แน่ใจว่ามีเฉพาะหัวข้อที่ต้องการฝึกอบรม โดยลบโลโก้ คนอื่นๆ พื้นที่ที่สูญเปล่า เป็นต้น.
ให้ฉันแสดงชุดข้อมูลที่ฉันได้มาสำหรับ Silvio Santos lora:

คุณสามารถเห็นได้ว่าพวกเขาทั้งหมดเป็นภาพบุคคล พื้นหลังและสีเสื้อผ้าที่แตกต่างกันเป็นสิ่งที่จำเป็น หน้าต้องมองไปในทิศทางที่แตกต่างกันด้วย.
หมายเหตุเกี่ยวกับความสมมาตร
ตรวจสอบว่าภาพทั้งหมดด้านซ้ายและขวาของบุคคลมีความสอดคล้องกันหรือไม่ ซึ่งอาจไม่เป็นเช่นนั้นกับเซลฟี่ที่มักจะกลับด้าน.
ใบหน้าของมนุษย์ไม่สมมาตร ดังนั้นหากคุณมีการจัดเรียงด้านผสมในระหว่างการฝึกอบรม ผลลัพธ์อาจเป็นเช่นนี้:

กรุณาตรวจสอบการจัดเรียง ของชุดข้อมูลทั้งหมดของคุณ!!
หากภาพตัวอย่างหลังจากผ่านไปสักระยะเริ่มมีลักษณะเหมือนกันทั้งหมด อาจเป็นสาเหตุนี้ เนื่องจาก SD จะพยายามเรียนรู้ทั้งสองด้านและความแตกต่างในความสมมาตรอาจทำให้การสูญเสียสูงขึ้นในบางภาพที่กลับด้าน จากนั้นการเรียนรู้จะติดอยู่ในบางภาพ.
จำนวนภาพ
- 5 ถึง 10: Lora ของคุณจะไม่มีความหลากหลายมากนัก แต่สามารถทำงานได้
- 11 ถึง 20: จุดที่ดี สามารถสร้าง Lora ที่ดีได้.
- 21 ถึง 50: ช่วงกว้างนี้คือสิ่งที่เราต้องการ!
- 50 ถึง 100: มากเกินไป แต่ทำงานได้เมื่อคุณต้องการเพิ่มภาพบุคคลและภาพเต็มตัวผสมกัน.
- มากกว่า 100: เสียเวลา.
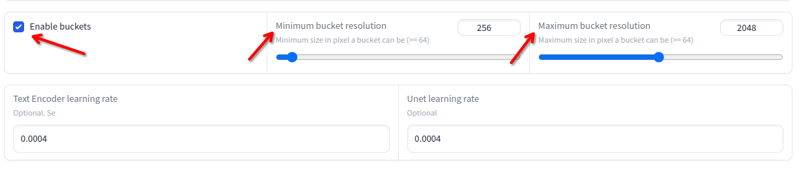
ความละเอียด
ความละเอียดสามารถแตกต่างกันได้ตั้งแต่ 256x ถึง 2048x หลีกเลี่ยงภาพที่ต่ำกว่าหรือสูงกว่าค่านี้ คุณไม่จำเป็นต้องปรับขนาดหากอยู่ในค่าดังกล่าว เนื่องจากการฝึกอบรมจะทำโดยอัตโนมัติในถัง:
โครงสร้างโฟลเดอร์:
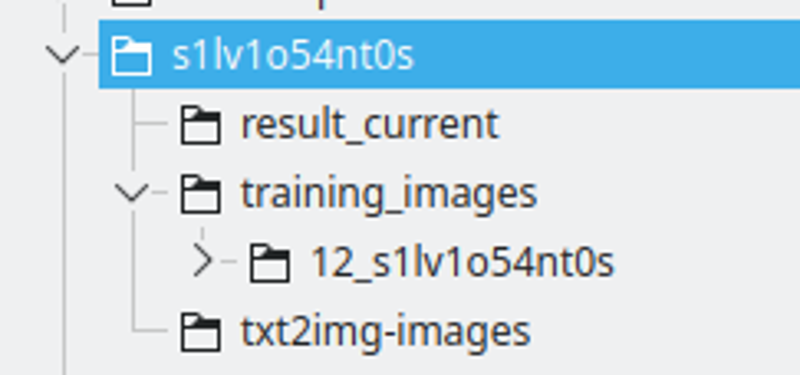
ฉันสร้างโฟลเดอร์ด้วยชื่อสตริง LoRA ฉันตั้งชื่อสตริงโดยการแทนที่ตัวอักษรบางตัวด้วยตัวเลข เพื่อให้แน่ใจว่าจะเป็นโทเค็นที่ไม่ซ้ำกันในหลายโมเดล.
ผลลัพธ์_current จะเป็นที่ที่ Kohya จะบันทึกผลลัพธ์
ภาพการฝึกอบรมจะมีไดเรกทอรีที่มีภาพการฝึกอบรม ชื่อแบบแผน คือ: 400 / จำนวนภาพ ขีดล่างและสตริง lora นี่จะเป็นจำนวนการทำซ้ำที่ Kohya จะทำ ฉันพบว่าหมายเลขนี้เป็นจุดที่ดีในการมีช่วงเวลาที่ดีระหว่าง epochs.
txt2img-images คือที่ที่ฉันเก็บภาพที่สร้างขึ้นโดยใช้ LoRA - ไม่บังคับ.
การอธิบายภาพ
นี่คือกระบวนการที่คุณจะอธิบายว่าแต่ละภาพคืออะไร จากนั้น SD จะรู้วิธีใช้โมเดลที่มีอยู่ในการสร้างภาพการฝึกอบรมจากเสียงรบกวน.
ใน Kohya ในแท็บยูทิลิตี้ เรามีการอธิบายภาพ Blip ฉันใช้สิ่งนี้ด้วยการตั้งค่าดังนี้:
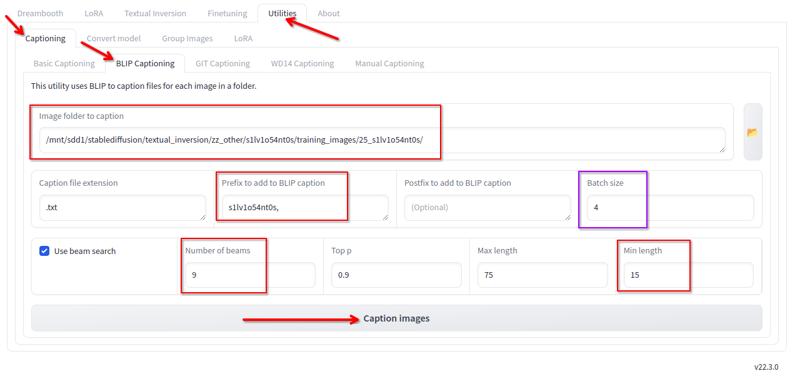
ฉันเปลี่ยนค่าดังต่อไปนี้:
- โฟลเดอร์ที่มีภาพอยู่.
- Prefix คือชื่อ lora และเครื่องหมายจุลภาค
- จำนวน beams 9
- ความยาวขั้นต่ำ 15
- ขนาดแบตช์ 4
- ค่าทั้งหมดอื่นๆ ฉันเก็บค่าเริ่มต้น.
คลิกที่การอธิบายภาพและมันจะสร้างคำบรรยายหลังจากผ่านไปสักครู่:
หากคุณมีภาพน้อย คุณอาจแก้ไขคำบรรยายได้ เนื่องจาก Blip ชอบเพิ่มวลีเช่น “ถือรีโมทคอนโทรล” หรือ “ถือไมโครโฟนในมือ” ซึ่งไม่เป็นความจริง ฉันแค่เพิกเฉยและมันก็ทำงานได้ดีในแบบนั้น เนื่องจากการอธิบายภาพโดยรวมดี.
*คุณอาจบอกว่าการอธิบายภาพ “พื้นฐาน” นี้ไม่ดีสำหรับ Flux ว่าการอธิบายภาพที่ดีกว่าด้วย LLM ดีกว่า แต่สำหรับฉันมันทำงานได้ดี.
โฟลเดอร์การควบคุม
ในอดีต สำหรับ Lora แรกที่ฉันเผยแพร่ ฉันใช้โฟลเดอร์การควบคุมที่มีภาพผู้หญิงมากกว่า 4K. ฉันหยุดใช้มัน เนื่องจากมันจำเป็นเมื่อชุดข้อมูลของคุณไม่มีการอธิบายภาพและมีความหลากหลายมากขึ้น.
การใช้มันจะทำให้เวลาที่ใช้และขั้นตอนเพิ่มเป็นสองเท่า.
ไม่ต้องใช้.
การรันการฝึกอบรม
ที่นี่เราจะรันการฝึกอบรม สำหรับ SD1.5 การตั้งค่าเหล่านี้ต้องการ 8GB Vram, SDXL ต้องการ 10GB Vram, Flux ต้องการ 16GB Vram.
การติดตั้ง Kohya นอกเหนือจากขอบเขตของคู่มือนี้.
การตั้งค่า Kohya
การตั้งค่า SD1.5: https://jsonformatter.org/a3213d
การตั้งค่า SDXL: https://jsonformatter.org/66e5c8
การตั้งค่า FLUX: https://jsonformatter.org/45c1fc
* แจ้งให้ฉันทราบหากลิงก์หมดอายุ
* สำหรับ FLUX, ฉันจำกัดการฝึกอบรมที่ 1800 ขั้นตอน (อยู่ในไฟล์การตั้งค่าข้างต้นแล้ว) แต่ประมาณ 1200 ขั้นตอน LoRA ก็ใช้ได้ดีแล้ว.
* นอกจากนี้สำหรับ FLUX, การตั้งค่าของฉันข้างบนไม่สามารถทำให้การฝึกอบรมสำหรับ ANIMES และ CARTOONS รวมกันได้ ดังนั้นคุณอาจต้องเพิ่ม –learning_rate=0.0004 –unet_lr=0.0004 เป็น 0.001 หรือ 0.002 ด้วยวิธีนี้การฝึกอบรมจะดีขึ้นในขั้นตอนที่น้อยลง แต่ก็อาจจะ overfit ได้ง่ายขึ้น.
เพียงแค่โหลดไฟล์เหล่านี้ในแท็บ Kohya LORA — ไม่ใช่แท็บ DREAMBOOT — คลิกที่ไฟล์การตั้งค่าและโหลดมัน.
การตั้งค่าที่คุณต้องเปลี่ยน:
ส่วนโมเดลและโฟลเดอร์:
- โฟลเดอร์ภาพ – โฟลเดอร์ training_images ที่เราสร้างขึ้นก่อนหน้านี้ ไม่ใช่โฟลเดอร์ที่มีหมายเลข โฟลเดอร์หลัก.
- โฟลเดอร์ผลลัพธ์ – โฟลเดอร์ result_current ที่เราสร้างขึ้นก่อนหน้านี้
- ชื่อผลลัพธ์ – ชื่อสตริงของ lora
แท็บพารามิเตอร์ > ขั้นสูง > ตัวอย่าง:
- เปลี่ยน prompt มันต้องง่าย จะใช้ในการสร้างภาพตัวอย่าง รักษาความเรียบง่าย
แท็บพารามิเตอร์ > พื้นฐาน:
- คุณอาจเปลี่ยนจำนวน epochs แต่ฉันจะเก็บไว้ที่ 6 เพื่อเริ่มต้น.
ค้นหาทางอินเทอร์เน็ตเกี่ยวกับความหมายของแต่ละฟิลด์ มันอยู่นอกเหนือจากขอบเขตในตอนนี้ที่จะอธิบายทั้งหมด แต่คุณสามารถอ่านได้ที่: พารามิเตอร์การฝึกอบรม LoRA
การใช้ฮาร์ดแวร์
การเปลี่ยนแปลงการตั้งค่ามักจะเปลี่ยนความต้องการฮาร์ดแวร์.
นี่คือสิ่งที่ทำงานสำหรับฉัน โดยใช้ RTX2060 super ที่มี Vram 12GB — สำหรับ FLUX ฉันอัปเกรดเป็น RTX 4060 TI 16GB Vram.
ตัวอย่างเช่น RTX2060 ของฉันไม่รองรับ bf16 เช่นเดียวกับ 3060s ดังนั้นฉันจึงใช้ fp16 ซึ่งจะช่วยประหยัดหน่วยความจำ แต่ก็เป็นเช่นนั้นและด้วย 12G ก็ทำงานได้.
หลังจากเปลี่ยนทั้งหมดนี้ คลิกที่ “เริ่มการฝึกอบรม”. คุณจะเห็นสิ่งนี้ในคอนโซล:
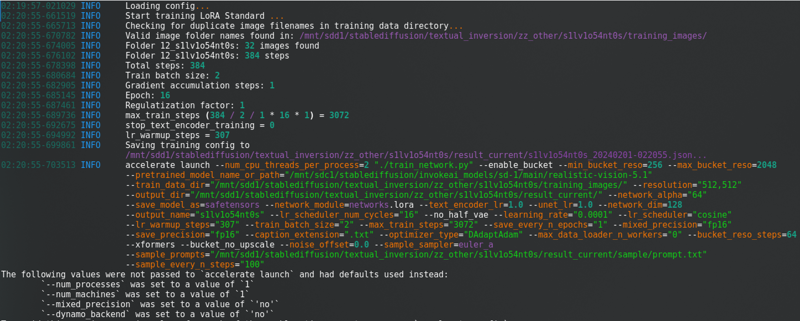
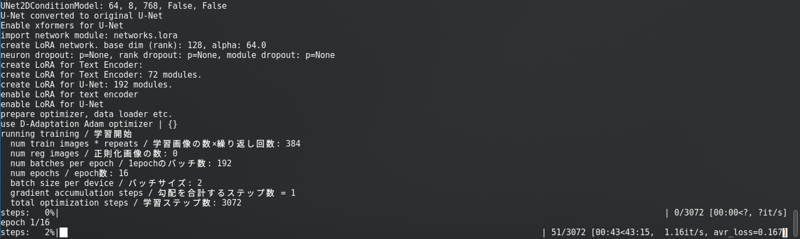
ด้วยแถบความก้าวหน้าที่ยาวมาก.
SD1.5: ฉันไม่เก็บ latents ลงในดิสก์ มันเร็วกว่า แต่ใช้ Vram เกือบเท่ากับ SDXL.
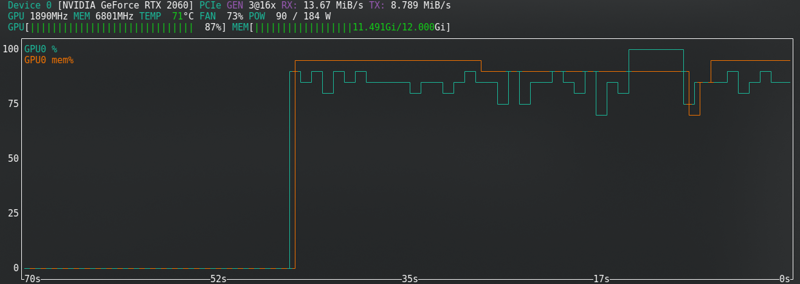

SDXL:
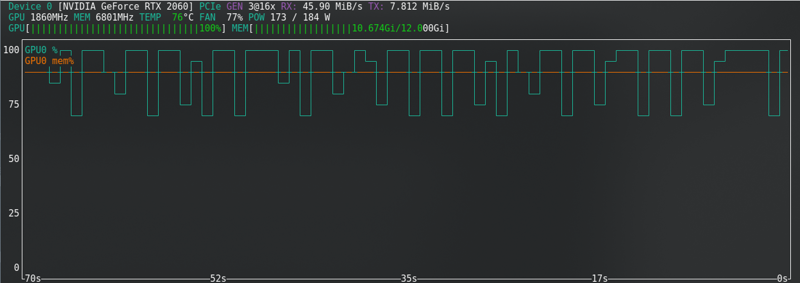

FLUX: ใกล้ขีดจำกัดแม้กับการ์ดใหม่!!!!!
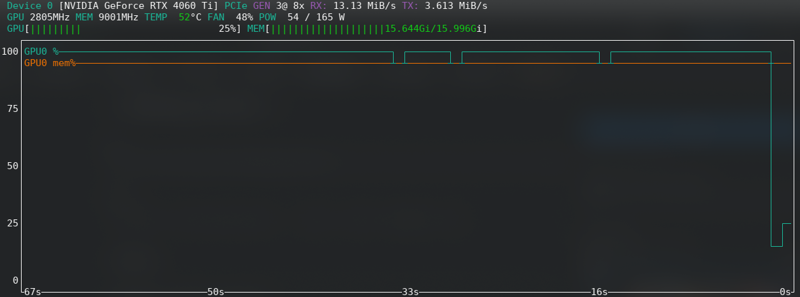
ข้อผิดพลาดหน่วยความจำหมด
หากคุณได้รับข้อผิดพลาด CUDA หน่วยความจำหมด แสดงว่าคุณถึงขีดจำกัดแล้ว. เปิดใช้งานการเก็บ latents ลงในดิสก์ เปลี่ยนจาก fp16 เป็น bf16 หากฮาร์ดแวร์ของคุณรองรับ ลดขนาดแบตช์จาก 2 เป็น 1.
สำหรับ Flux คุณสามารถเปิดใช้งาน “โหมดแยก” ซึ่งจะลด VRAM ได้มาก แต่จะเพิ่มเวลาการฝึกอบรมเป็นสองเท่า.
ตัวเลือกอื่นๆ ได้แก่: ปิดโปรแกรมทั้งหมด ถอดการเชื่อมต่อจอภาพที่สองของคุณ ลดความละเอียดของจอภาพ หากใช้ Linux ให้เปลี่ยนไปใช้สภาพแวดล้อมเดสก์ท็อปที่เบากว่าเป็นการชั่วคราว เมื่อเริ่มการฝึกอบรมให้ปิดเบราว์เซอร์และตรวจสอบสถานะเฉพาะกับพรอมต์คำสั่งที่เปิดอยู่.
หากคุณไม่สามารถแก้ไขได้ ค้นหาทางอินเทอร์เน็ต หากยังคงได้รับข้อผิดพลาด ให้ยอมแพ้และฝึกอบรมใน CivitAI.
การแสดงตัวอย่างการฝึกอบรม
ทุกๆ 100 ขั้นตอน (คุณสามารถเปลี่ยนได้) การฝึกอบรมจะสร้างภาพตัวอย่างในโฟลเดอร์ results_current/sample จากนั้นคุณจะมีแนวคิดว่ามันทำงานหรือไม่.
ผลลัพธ์จะดีขึ้นตามเวลาเมื่อมันเรียนรู้.

ผลการฝึกอบรม
เมื่อมันเสร็จสิ้น โฟลเดอร์จะมีลักษณะดังนี้:
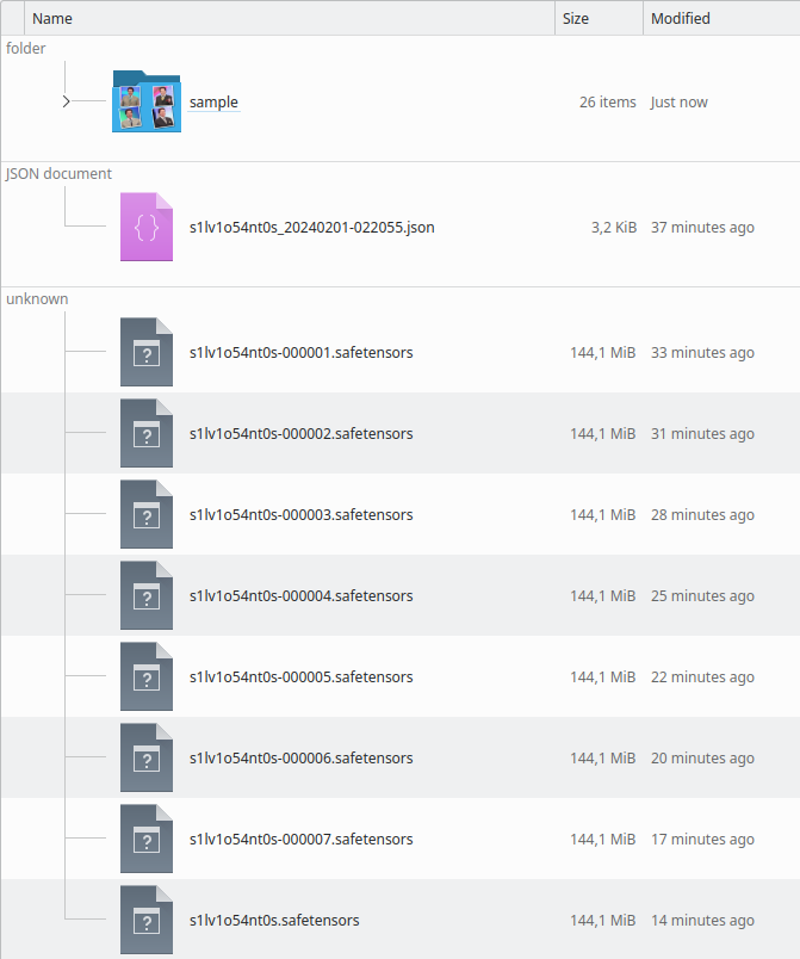
คุณสามารถตรวจสอบจากภาพตัวอย่างว่ามันถูกฝึกมากเกินไปหรือไม่เพียงพอ คุณจะเห็นเมื่อรัน LoRA ด้วย.
ฝึกมากเกินไป
หากโมเดลถูกฝึกมากเกินไป ภาพจะมีลักษณะ “พิกเซลที่ทำจากดิน”... ฉันไม่รู้จะอธิบายอย่างไร ภาพตัวอย่างจะเริ่มบิดเบือน.
ดูด้วยตาของคุณ ภาพที่สร้างขึ้น:

บางครั้งมันอาจไม่เกิดผลลัพธ์ที่แย่ขนาดนี้ แต่ใบหน้าจะหยุดดูเหมือนบุคคลที่ถูกฝึกจนกว่าจะบิดเบือนใน epochs ถัดไป.

ทางออกนั้นง่าย: เพียงแค่ทดสอบ epochs ก่อนหน้านี้และดูว่าอันไหนล่าสุดที่ทำงานได้ดี โดยอิงจากภาพตัวอย่างคุณสามารถหาภาพที่ดีและค้นหาไฟล์ LoRA ที่สร้างขึ้นในช่วงเวลาเดียวกัน.
มันยากที่จะเลือกหนึ่ง!!! แต่ต้องทำ ทดสอบให้มากที่สุดเท่าที่จะทำได้.
ฝึกน้อยเกินไป
หากมันถูกฝึกน้อยเกินไป (ใบหน้าภาพบุคคลไม่ดูเหมือนบุคคลและดูเหมือนเป็นการรวมกันของบุคคลทั่วไปจากโมเดล SD หรือวัตถุไม่มีรายละเอียดที่ต้องการ) คุณสามารถดำเนินการฝึกอบรมต่อ.

ในภาพตัวอย่างนี้คุณจะเห็นว่ามีรายละเอียดขาดหายไป เช่น ไมโครโฟนที่รวมกับเนคไท.
ความแตกต่างจากการฝึกมากเกินไปคือการขาดรายละเอียด.
หากคุณปิด Kohya ไม่มีปัญหา เพียงแค่โหลด json ที่มันสร้างขึ้นในไดเรกทอรีผลลัพธ์และการตั้งค่าทั้งหมดที่ใช้จะถูกโหลด.
ใน Parameters > Basic คุณมีฟิลด์ น้ำหนักเครือข่าย LoRA ที่คุณสามารถเพิ่ม lora ใดๆ ที่คุณต้องการฝึกต่อ.
เปลี่ยนชื่อไฟล์ล่าสุดที่คุณได้มาเป็นชื่ออื่น คัดลอกตำแหน่งของมันไปยังฟิลด์นี้ เปลี่ยน epochs เป็น 2 หรือ 3 (ขึ้นอยู่กับว่าคุณต้องการฝึกนานแค่ไหน) และคลิกที่ เริ่มการฝึกอบรม อีกครั้ง มันจะดำเนินการฝึกอบรมต่อ.
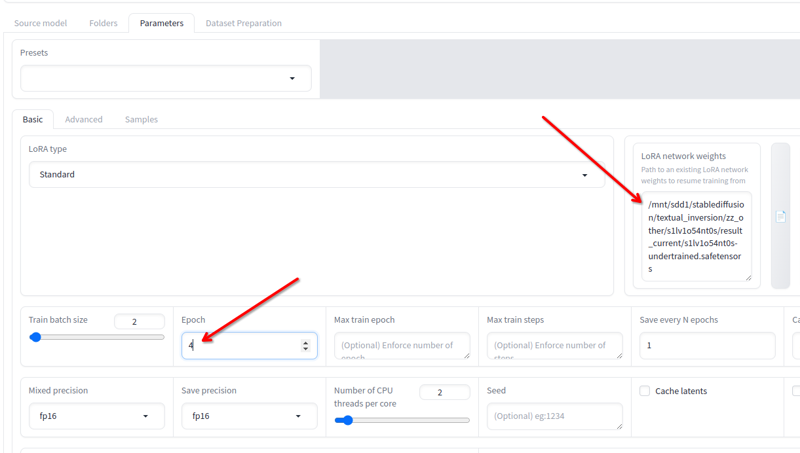
คุณสามารถทำเช่นนี้จนกว่าจะดี!
เสร็จสิ้น!
เปลี่ยนชื่อ Lora สุดท้ายที่คุณต้องการ (หรือเก็บไว้หากผลลัพธ์สุดท้ายดี) และใช้งาน.
นี่คือ ตัวอย่าง SD1.5:

นี่คือ ตัวอย่าง Flux:






