
如何训练NSFW LoRA(FLUX更新版)
g
By gerogero
Updated: March 13, 2026
用于训练的模型
对于 SD 1.5 真实照片:
- 训练:Realistic Vision 5.1
这个模型是在合并时添加的,也是合并的一部分。它与几乎所有其他真实模型都能很好配合。出于某种原因,v6 的效果并不好。 - 生成:Realistic Vision 5.1,以及使用PicX Real 1.0进行的 denoise 为 0.1 的 img2img。单独使用 RV 也能完成工作,但我喜欢这个组合。
对于 SD 1.5 动漫:
- 训练:AnyLora
这是一个经典的训练模型。 - 生成:Azure Anime v5
对于 SDXL 整体(包括 Pony 和 Illustrious):
- 训练:SDXL 基础模型
- 生成:Dreamshaper XL Turbo。我使用 7 步,然后用相同的提示但新的种子进行 img2img,结果很好!
对于 FLUX 整体:
- 模型:flux1-Dev-Fp8.safetensors(11.1 GB 文件)
- VAE:ae.safetensors
- Clip:clip_l.safetensors
- T5 编码器:t5xxl_fp8_e4m3fn.safetensors
- 需要 16GB 的显存。但你可以尝试这篇文章。
我使用的工具
- 训练时需要安装:Kohya_ss
但有时我会运行我自己编写的脚本来加快过程,它会调用 Kohya 脚本并设置所有参数。我会在最后谈到它。
需要使用sd3-flux.1分支来进行 Flux。 - 生成:InvokeAI
抱歉大家,我这里有 Automatic1111 和 ComfyUI,但我喜欢 InvokeAI。 - Lora 元数据查看器: https://civitai.com/models/249721
数据集准备
这是最重要的部分。你必须收集你想要训练的人、物体或其他任何东西的图像。
需要考虑的一些事项
- 避免低分辨率或像素化的图像。我不推荐放大。
- 避免图像之间差异过大。我通常坚持使用肖像。
- 避免化妆过多、耳环和项链过多、姿势奇怪的图像。
- 手。避免手出现在奇怪位置的图像。
- 我逐一裁剪,以确保只包含要训练的主题,去除标志、其他人、浪费的空间等。
让我展示一下我为 Silvio Santos lora 收集的数据集:

你可以看到它们都是肖像。不同的背景和衣服颜色是必须的。面孔也要朝向不同的方向。
关于对称性的说明
检查所有图像中人物的左右两侧是否一致。这在自拍中可能不是这样,因为自拍通常是反转的。
人脸并不对称,因此如果在训练过程中有混合的侧面朝向,结果可能会是这样的:

请检查你整个数据集的朝向!!
如果预览图像在一段时间后开始变得完全相同,这可能是原因,因为 SD 会尝试学习两侧的内容,而对称性差异可能导致某些反转图像的损失略高,因此学习会停留在少数几张图像上。
图像数量
- 5 到 10:你的 Lora 不会有太多变化,但可以工作
- 11 到 20:不错的范围。可以生成一个好的 lora。
- 21 到 50:这个宽范围是我们想要的!
- 50 到 100:太多,但在你想添加肖像和全身混合时有效。
- > 100:浪费工作。
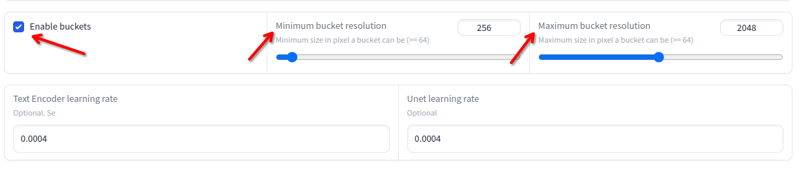
分辨率
分辨率可以在 256x 到 2048x 之间变化。避免低于或高于这些值的图像。如果它们在这些值之间,你不需要调整大小,因为训练会自动在桶中完成:
文件夹结构:
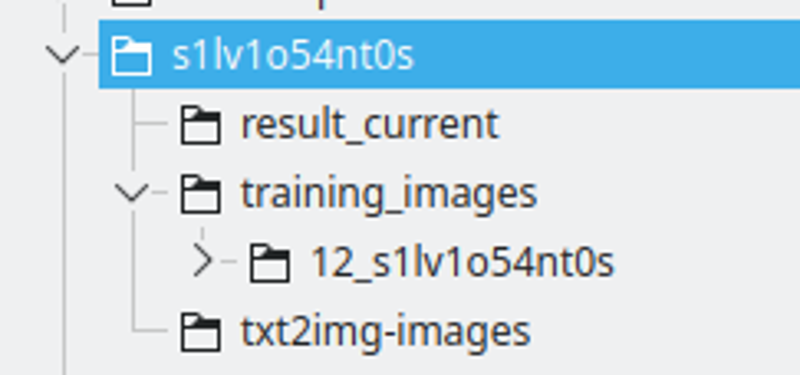
我创建一个以 LoRA 字符串命名的文件夹。我用数字替换一些字母来命名字符串,以确保它在多个模型中是唯一的标记。
result_current 将是 Kohya 保存结果的地方
训练图像将包含训练图像的目录。命名约定为:400 / 图像数量,一个下划线和 lora 字符串。这将是 Kohya 进行重复的次数。我发现这个数字是一个不错的选择,可以在每个周期之间保持良好的间隔。
txt2img-images 是我使用 LoRA 生成的图像存储位置 - 可选。
图像描述
这是描述每张图像的过程,然后 SD 将知道如何使用现有模型从噪声中构建训练图像。
在 Kohya 的实用工具选项卡中,我们有 Blip 描述。我使用这些配置:
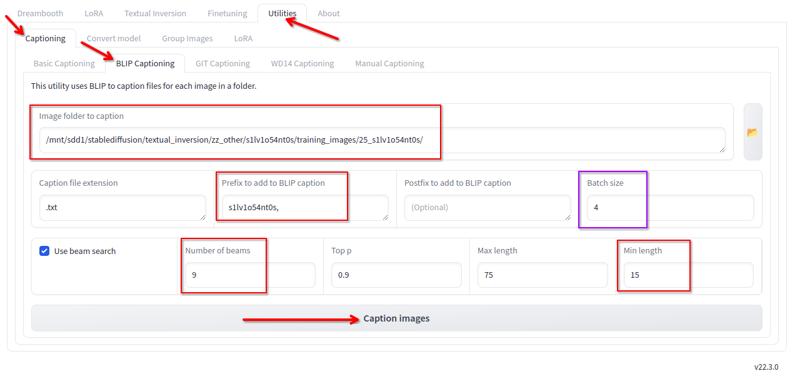
我更改以下内容:
- 图像所在的文件夹。
- 前缀是 lora 名称和一个逗号
- 光束数量 9
- 最小长度 15
- 批量大小 4
- 其他所有值我保持默认。
点击描述,它会在一段时间后生成描述:
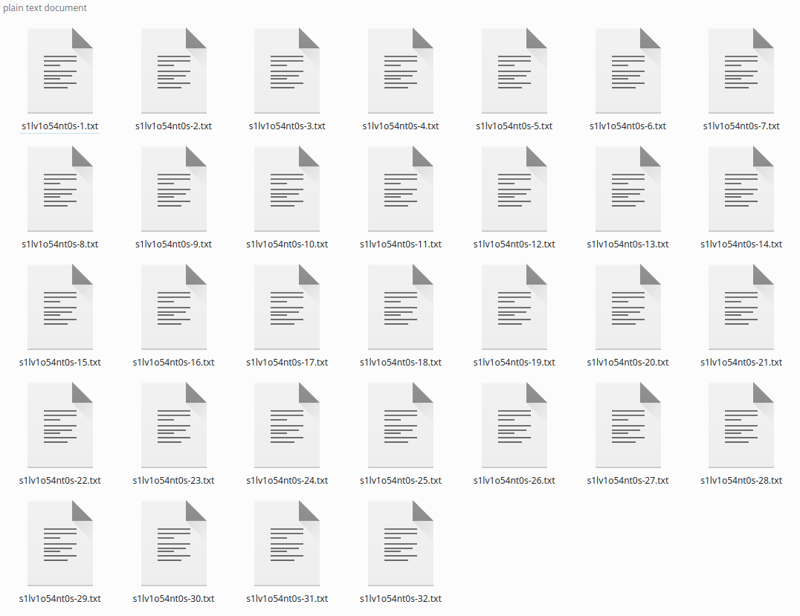
如果你有少量图像,你可以修正描述,因为 Blip 喜欢添加“拿着遥控器”或“手里拿着麦克风”等短语,而这些并不真实。我只是忽略它,这样做效果很好,因为整体描述质量不错。
*你可能会说这种“基本”描述对 Flux 不太好,更好的描述使用 LLM 更好,但对我来说效果很好。
正则化文件夹
在过去,我发布的第一个 lora 使用了一个包含超过 4K 女性图像的正则化文件夹。我停止使用它,因为它仅在你的数据集没有描述且更为多样时才需要。
使用它将使所需时间和步骤翻倍。
不要使用。
运行训练
在这里我们将运行训练。对于 SD1.5,这些配置需要 8GB 显存,SDXL 需要 10GB 显存,Flux 需要 16GB 显存。
安装 Kohya 超出了本指南的范围。
Kohya 配置
SD1.5 配置: https://jsonformatter.org/a3213d
SDXL 配置: https://jsonformatter.org/66e5c8
FLUX 配置: https://jsonformatter.org/45c1fc
* 如果链接过期,请告诉我
* 对于 FLUX,我将训练限制在 1800 步(已在上述配置文件中),但在 1200 步时,LoRA 已经很好了。
* 同样对于 FLUX,我上面的设置没有使训练收敛于动漫和卡通。因此,你可能需要将 –learning_rate=0.0004 –unet_lr=0.0004 增加到 0.001 或 0.002。这样训练在更少的步骤中变得很好,但可能更容易过拟合。
只需在 Kohya LORA 选项卡 — 不是 DREAMBOOT 选项卡 — 中加载这些文件,点击配置文件并加载。
必须更改的配置:
模型和文件夹部分:
- 图像文件夹 - 我们之前创建的 training_images 文件夹。不是带有数字的文件夹,而是父文件夹。
- 输出文件夹 - 我们之前创建的 result_current 文件夹
- 输出命名 - lora 的字符串名称
参数选项卡 > 高级 > 样本:
- 更改提示。它必须简单,将用于生成样本图像。保持简单
参数选项卡 > 基本:
- 你可以更改周期数,但我建议开始时保持 6。
在网上搜索每个字段的含义,解释它们超出了本指南的范围,但你可以在这里阅读: LoRA 训练参数
硬件利用率
大多数配置会改变硬件要求。
这些是我使用 RTX2060 super 12GB 显存时有效的配置 - 对于 FLUX,我升级到了 RTX 4060 TI 16GB 显存。
例如,我的 RTX2060 不支持 bf16 像 3060s,因此我使用 fp16。这会节省内存,但就是这样,12G 的显存也能正常工作。
更改所有这些后,点击“开始训练”。你会在控制台中看到:
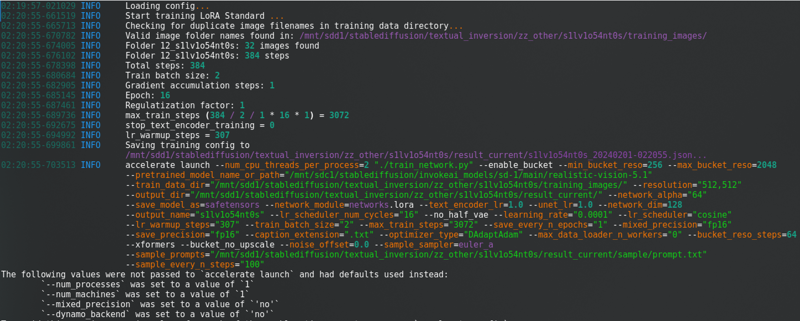
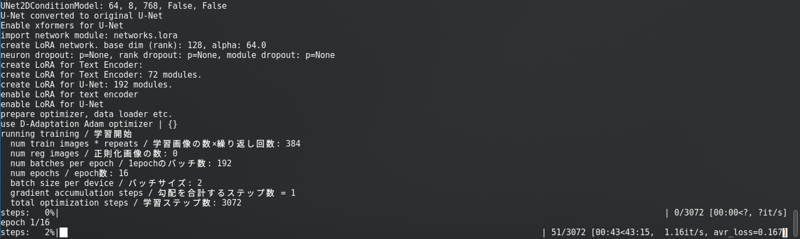
有一个很长的进度条。
SD1.5:我不将潜在值缓存到磁盘。这更快,但几乎使用与 SDXL 相同的显存。
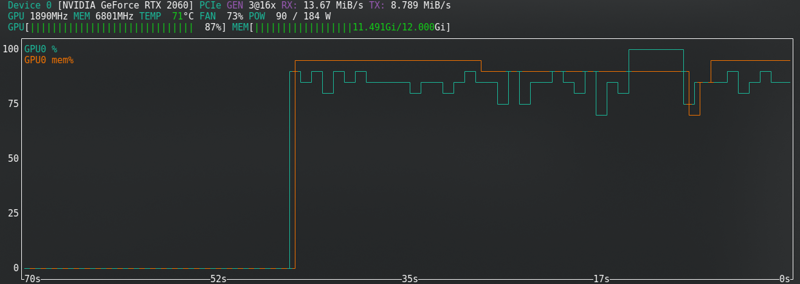

SDXL:
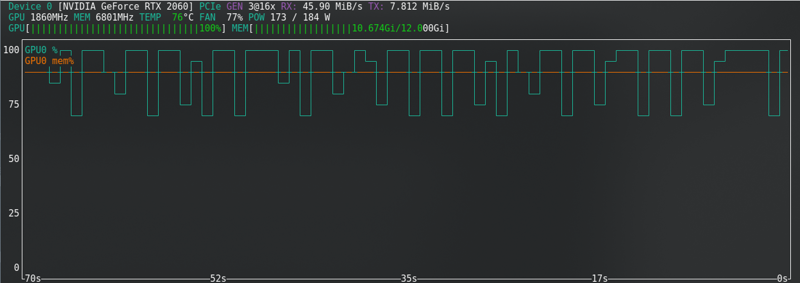

FLUX:即使使用新卡也接近极限!!!!!
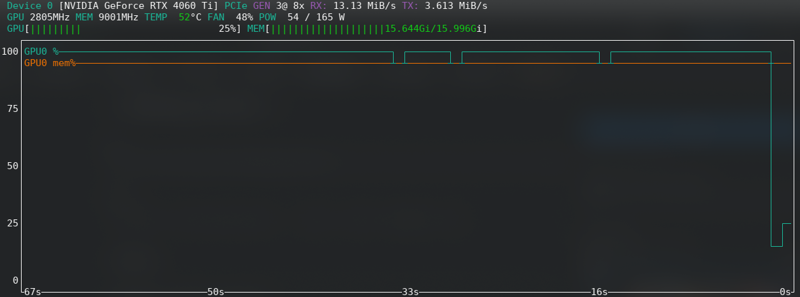
内存不足错误
如果你收到 CUDA 内存不足错误,那么你已经达到了极限。启用潜在值缓存到磁盘,如果你的硬件支持,将 fp16 更改为 bf16,减少批量大小从 2 到 1。
对于 Flux,你可以启用“分割模式”。这会大大减少显存,但几乎会将训练时间翻倍。
其他选项包括:关闭所有程序,断开第二个显示器,降低显示分辨率,如果在 Linux 上暂时切换到更轻量的桌面环境,一旦触发训练,关闭浏览器,仅用命令提示符检查状态。
如果你无法解决,搜索互联网。如果仍然出现错误,那就放弃并在 CivitAI 上训练。
训练预览
每 100 步(你可以更改)训练将创建一张样本图像在 results_current/sample 文件夹中,这样你就可以了解它是否有效。
随着学习的进行,结果会随着时间而改善。

训练结果
当训练完成时,目录将如下所示:
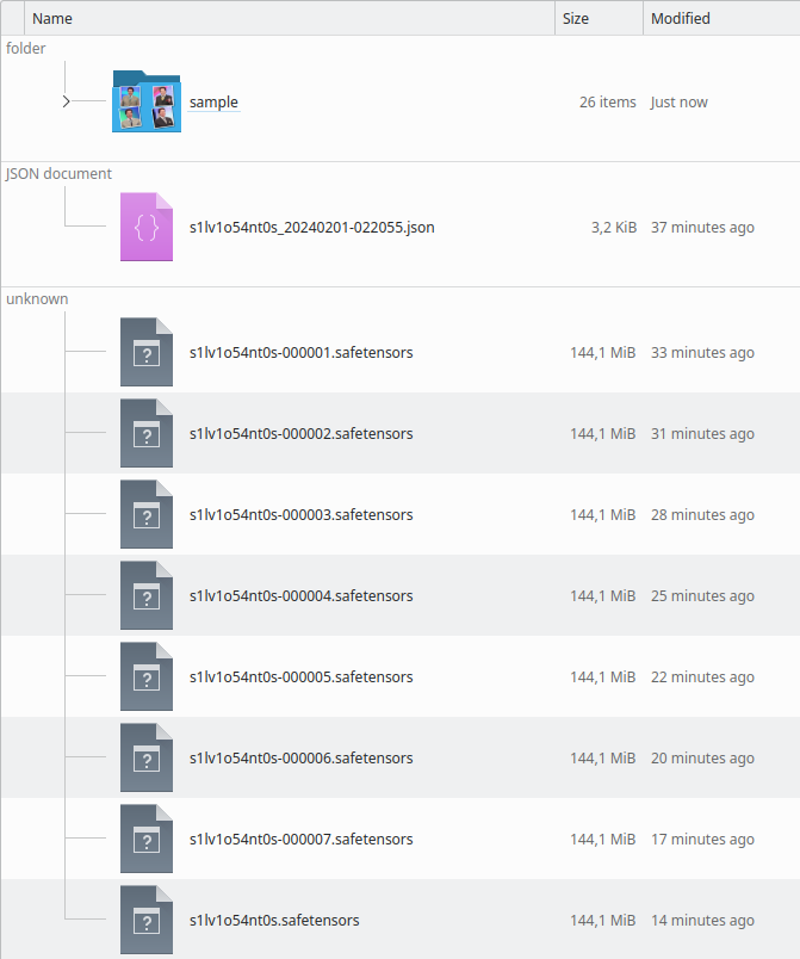
你可以通过样本图像检查它是否过度训练或不足训练。运行 LoRA 时也会看到这一点。
过度训练
如果模型过度训练,图像将会“像粘土一样像素化”……我不知道该如何描述。预览图像将开始失真。
看看生成的图像:

有时不会得到如此糟糕的结果,但面孔会停止看起来像训练过的人,直到在后面的周期中变形。

解决方案很简单: 只需测试之前的周期,查看最近的一个效果良好的周期。根据样本图像,你可以轻松找到好的结果,并找到在同一时间生成的 LoRA 文件。
选择一个是很困难的!!!但必须完成。尽可能多地测试。
不足训练
如果它不足训练(肖像面孔看起来不像这个人,似乎是 SD 模型中的通用人,或者物体还没有所需的细节),你可以恢复训练。

在这个示例图像中,你可以看到细节缺失,比如麦克风与领带合并。
与过度训练的区别在于缺乏细节。
如果你关闭了 Kohya,没关系,只需加载它在结果目录中创建的 json 文件,所有使用的配置将被加载。
在参数 > 基本中,你有LoRA 网络权重字段,你可以添加任何你想继续训练的 lora。
将你得到的最后一个重命名为其他名称,将其位置复制到此字段中,将周期数更改为 2 或 3(这取决于你需要多少继续训练),然后再次点击开始训练。它将恢复训练。
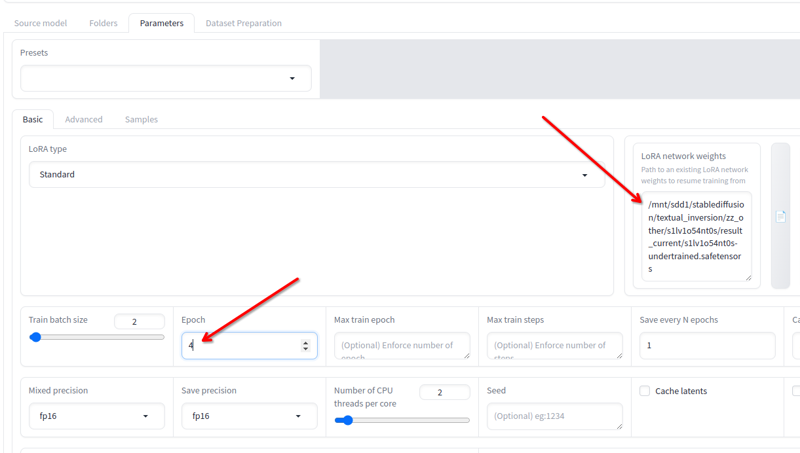
你可以这样做直到它变得好!
完成!
重命名你想要的最终 lora 周期(如果最终结果好就保留),并使用它。
这是 SD1.5 示例:

这是 Flux 示例:






