
如何訓練NSFW LoRA(FLUX更新版)
g
By gerogero
Updated: March 13, 2026
用於訓練的模型
對於 SD 1.5 真實照片:
- 訓練: Realistic Vision 5.1
這個模型是在合併時添加的,並且也是合併的一部分。它與幾乎所有其他真實模型都能很好地配合使用。出於某種原因,v6 的效果不如預期。 - 生成: Realistic Vision 5.1,並使用 PicX Real 1.0進行 img2img 生成,去噪值為 0.1。單獨使用 RV 也能完成工作,但我喜歡這個組合。
對於 SD 1.5 動漫:
- 訓練: AnyLora
這是一個經典的訓練模型。 - 生成: Azure Anime v5
對於 SDXL 整體(包括 Pony 和 Illustrious):
- 訓練: SDXL 基本模型
- 生成: Dreamshaper XL Turbo。我使用 7 步驟,然後用相同的提示詞但新的隨機種子進行 img2img,結果非常好!
對於 FLUX 整體:
- 模型: flux1-Dev-Fp8.safetensors (11.1 GB 文件)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 編碼器: t5xxl_fp8_e4m3fn.safetensors
- 需要 16GB 顯存。但你可以嘗試 這篇文章。
我使用的工具
- 訓練需要安裝: Kohya_ss
但有時我會運行我自己編寫的腳本來加快過程,它會調用 Kohya 腳本並設置所有參數。我會在最後談到這個。
需要使用 sd3-flux.1分支來進行 Flux。 - 生成: InvokeAI
抱歉大家,我這裡有 Automatic1111 和 ComfyUI,但我喜歡 InvokeAI。 - Lora 元數據查看器: https://civitai.com/models/249721
數據集準備
這是最重要的部分。你需要收集來自人物、物體或任何你想訓練的東西的圖片。
需要考慮的一些事項
- 避免低解析度或像素化的圖片。我不建議進行放大。
- 避免彼此差異過大的圖片。我通常專注於肖像。
- 避免過多化妝、耳環和項鍊、奇怪姿勢的圖片。
- 手。避免手出現過多且位置奇怪的圖片。
- 我會逐一裁剪,以確保只包含訓練主題,去除標誌、其他人、浪費的空間等。
讓我展示我為 Silvio Santos lora 收集的數據集:

你可以看到它們都是肖像。不同的背景和衣服顏色是必須的。面孔朝向不同的方向也是。
有關對稱的注意事項
檢查所有圖片中人物的左右側是否一致。自拍照通常會出現反轉的情況。
人臉不是對稱的,因此如果在訓練過程中有混合的側面方向,結果可能會是這樣:

請檢查你的整個數據集的方向!!
如果預覽圖片在一段時間後開始變得都一樣,這可能是原因,因為 SD 會嘗試學習兩側的特徵,對稱的差異可能會導致某些反轉圖片的損失略高,從而使學習停滯在少數幾張圖片上。
圖片數量
- 5 到 10:你的 Lora 不會有太多變化,但可以工作
- 11 到 20:不錯的範圍。可以生成一個不錯的 lora。
- 21 到 50:這個範圍正是我們所希望的!
- 50 到 100:太多,但當你想添加肖像和全身混合時可以使用。
- > 100:浪費工作。
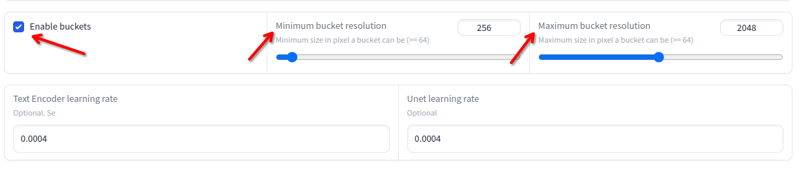
解析度
解析度可以從 256x 到 2048x 變化。避免低於或高於這些值的圖片。如果它們在這些值之內,你不需要調整大小,因為訓練會自動在桶中處理:
文件夾結構:
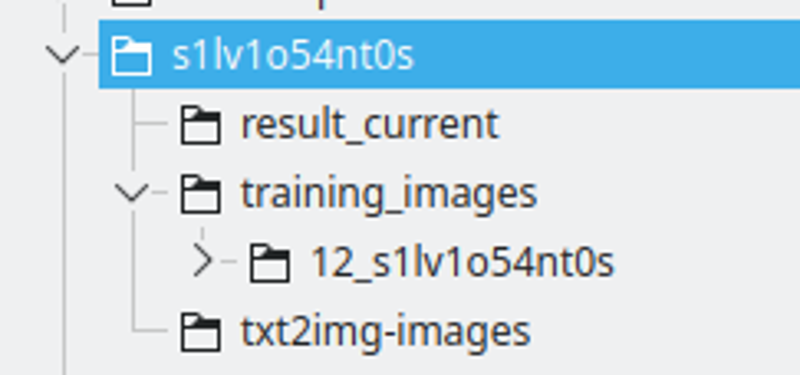
我創建一個以 LoRA 字串命名的文件夾。我將字串中的某些字母替換為數字,以確保它在多個模型中是唯一的標記。
result_current 將是 Kohya 保存結果的地方
訓練圖片將包含訓練圖片的目錄。命名規則為:400 / 圖片數量,底線和 lora 字串。這將是 Kohya 進行重複的次數。我發現這個數字是一個不錯的範圍,可以在每個訓練週期之間保持良好的間隔。
txt2img-images 是我使用 LoRA 生成的圖片存儲位置 - 可選。
標題生成
這是描述每張圖片的過程,然後 SD 將知道如何使用現有模型從噪聲中構建訓練圖片。
在 Kohya 的工具選項卡中,我們有 Blip 標題生成。我使用這些配置:
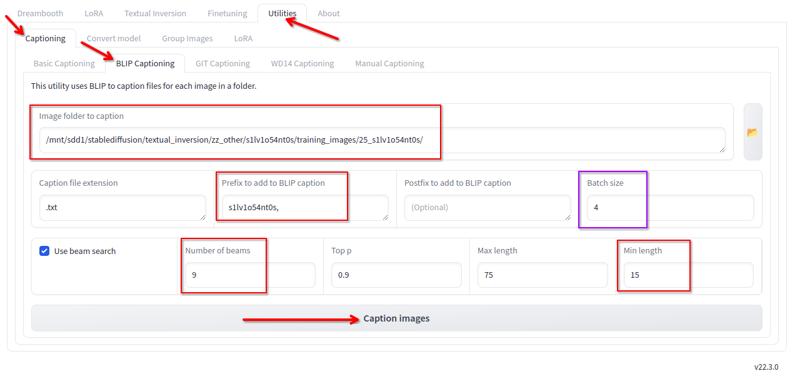
我更改以下內容:
- 圖片所在的文件夾。
- 前綴是 lora 名稱和一個逗號
- 光束數量 9
- 最小長度 15
- 批次大小 4
- 其他所有值我保持默認。
點擊標題生成,過一會兒,它將生成標題:
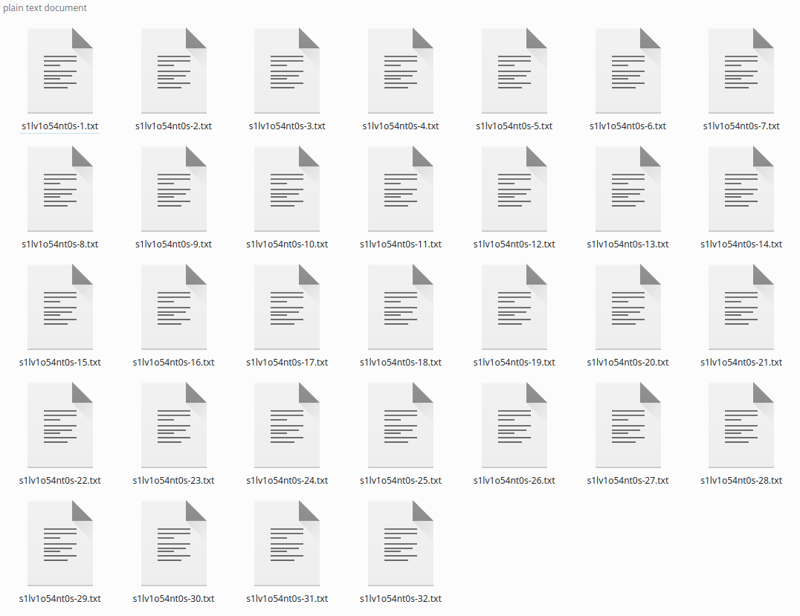
如果你有少量圖片,你可能需要修正標題,因為 Blip 喜歡添加像“手持遙控器”或“手中拿著麥克風”的短語,這並不真實。我只是忽略它,這樣整體標題生成效果還不錯。
*你可能會說這種“基本”的標題生成對於 Flux 來說不太好,更好的標題生成使用 LLM 會更好,但對我來說這樣的效果很好。
正則化文件夾
在過去,我發布的第一批 lora 使用了一個包含超過 4K 女性圖片的正則化文件夾。我停止使用它,因為當你的數據集沒有標題且更為多樣時才需要它。
使用它將使所需的時間和步驟加倍。
不要使用。
運行訓練
在這裡我們將運行訓練。對於 SD1.5,這些配置需要 8GB 顯存,SDXL 需要 10GB 顯存,Flux 需要 16GB 顯存。
安裝 Kohya 超出了本指南的範疇。
Kohya 配置
SD1.5 配置: https://jsonformatter.org/a3213d
SDXL 配置: https://jsonformatter.org/66e5c8
FLUX 配置: https://jsonformatter.org/45c1fc
* 如果鏈接過期請告訴我
* 對於 FLUX,我將訓練限制在 1800 步(已在上面的配置文件中)但在約 1200 步時,LoRA 已經很好了。
* 同樣對於 FLUX,我上面的設置對於動漫和卡通的訓練沒有收斂。因此,你可能需要將 –learning_rate=0.0004 –unet_lr=0.0004 增加到 0.001 或 0.002。這樣訓練在較少的步驟中變得良好,但可能更容易過擬合。
只需將這些文件加載到 Kohya 的LORA 標籤 — 不是 DREAMBOOT 標籤 — 點擊配置文件並加載它。
必須更改的配置:
模型和文件夾部分:
- 圖片文件夾 - 我們之前創建的 training_images 文件夾。不是帶有數字的文件夾,而是父文件夾。
- 輸出文件夾 - 我們之前創建的 result_current 文件夾
- 輸出命名 - lora 的字串名稱
參數標籤 > 高級 > 樣本:
- 更改提示詞。它必須簡單,將用於生成樣本圖片。保持簡單
參數標籤 > 基本:
- 你可以更改訓練週期的數量,但我建議先保持 6。
在互聯網上搜索每個字段的含義,現在不在範疇內解釋所有內容,但你可以在這裡閱讀: LoRA 訓練參數
硬體利用率
大多數配置會改變硬體需求。
這些是我使用的配置,使用 RTX2060 super 具有 12GB 顯存 - 對於 FLUX,我升級到 RTX 4060 TI 16GB 顯存。
例如,我的 RTX2060 不支持 bf16 像 3060s,因此我使用 fp16。這樣可以節省內存,但就是這樣,12G 的顯存也能正常運行。
更改所有這些後,點擊“開始訓練”。你會在控制台中看到這個:
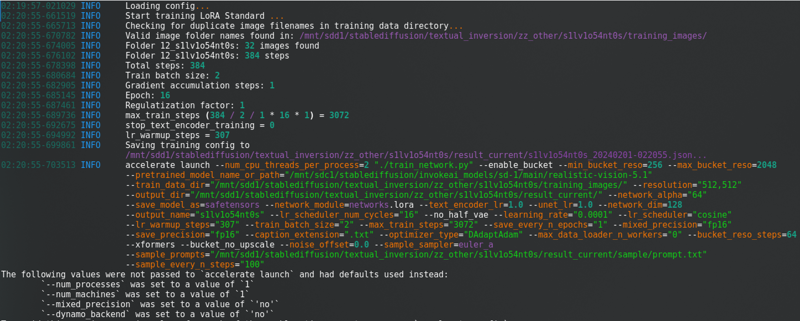
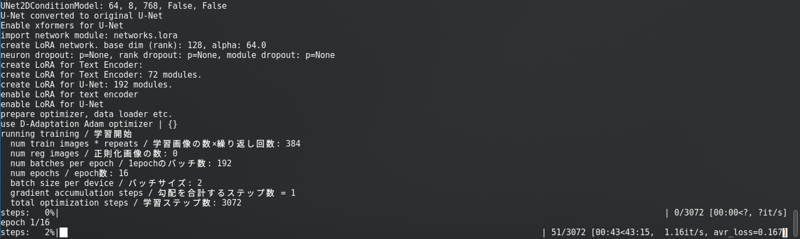
有一個很長的進度條。
SD1.5: 我不將潛在變量緩存到磁碟。這樣更快,但使用的顯存幾乎與 SDXL 相同。
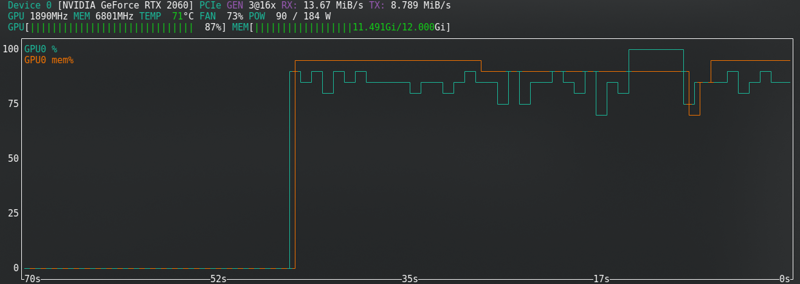

SDXL:
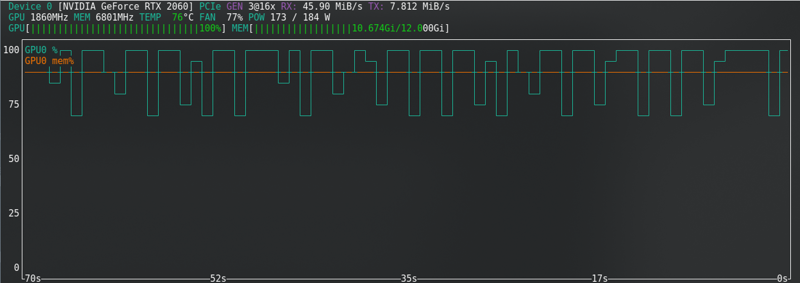

FLUX:即使使用新卡也接近極限!!!!!
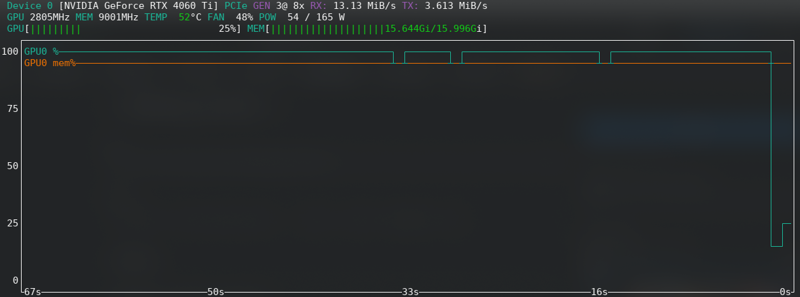
內存不足錯誤
如果你收到 CUDA 內存不足的錯誤,那麼你已經達到極限。啟用潛在變量緩存到磁碟,如果你的硬體支持,將 fp16 更改為 bf16,將批次大小從 2 減少到 1。
對於 Flux,你可以啟用“分割模式”。這樣可以大大減少顯存,但幾乎會將訓練時間加倍。
其他選項包括:關閉所有程序,斷開第二個顯示器,降低顯示解析度,如果在 Linux 上暫時更改為輕量級桌面環境,一旦觸發訓練,關閉瀏覽器並僅通過命令提示符檢查狀態。
如果你無法解決,請在互聯網上搜索。如果仍然出現錯誤,那就放棄並在 CivitAI 上訓練。
訓練預覽
每 100 步(你可以更改)訓練將在 results_current/sample 文件夾中創建一個樣本圖片,這樣你就可以了解它是否在正常運行。
隨著訓練的進行,結果會隨著時間改善。

訓練結果
當訓練結束時,目錄將如下所示:
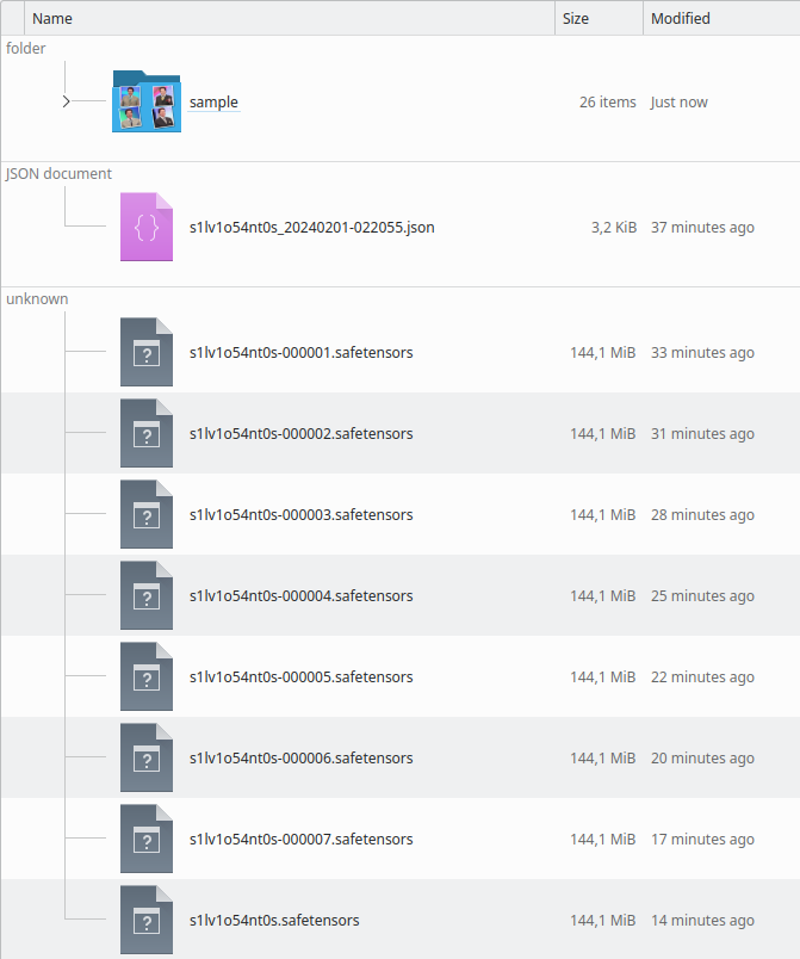
你可以通過樣本圖片檢查它是否過度訓練或訓練不足。你在運行 LoRA 時也會看到這一點。
過度訓練
如果模型過度訓練,圖片將會“像泥土一樣像素化”……我不知道該怎麼描述。預覽圖片將開始失真。
看看生成的圖片:

有時它不會得到這麼糟糕的結果,但面孔會停止看起來像訓練過的人,直到在後面的訓練週期中變形。

解決方案很簡單: 只需測試之前的訓練週期,查看最近的那個效果良好。根據樣本圖片,你可以輕鬆找到好的訓練結果,並找到大約在同一時間生成的 LoRA 文件。
選擇一個是很難的!!!但必須這樣做。盡量多測試。
訓練不足
如果訓練不足(肖像面孔看起來不像那個人,似乎是 SD 模型中的通用人物,或者物體尚未具有所需的細節),你可以恢復訓練。

在這個示例圖片中,你可以看到缺少細節,例如麥克風與領帶合併。
過度訓練的區別在於缺乏細節。
如果你關閉了 Kohya,沒問題,只需加載它在結果目錄中創建的 json,所有使用的配置將會加載。
在參數 > 基本中,你有LoRA 網絡權重字段,可以添加任何你想繼續訓練的 lora。
將你獲得的最後一個文件重命名為其他名稱,將其位置複製到此字段,將訓練週期更改為 2 或 3(這取決於你需要多少次繼續訓練),然後再次點擊開始訓練。這將恢復訓練。
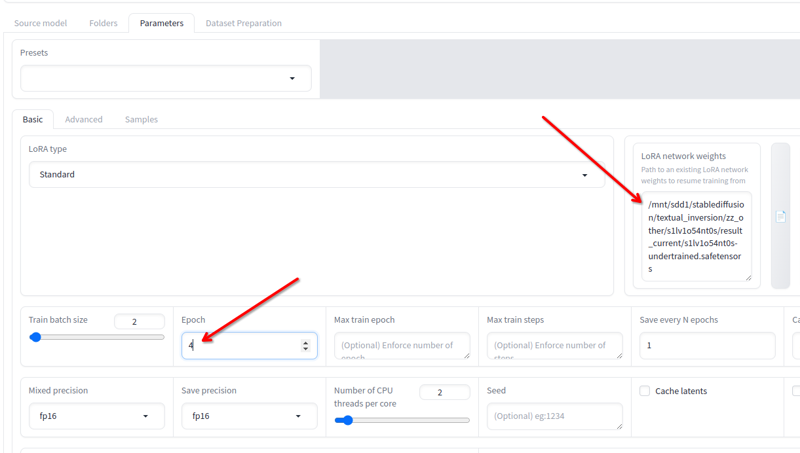
你可以這樣做直到它變得好為止!
完成!
重命名你想要的最終 lora 訓練週期(如果最終結果不錯則保留),並使用它。
這是SD1.5 的示例:

這是Flux 的示例:






