
Comment entraîner un LoRA NSFW (mis à jour avec FLUX)
g
By gerogero
Updated: March 13, 2026
Modèles utilisés pour l'entraînement
Pour SD 1.5 photos réalistes :
- Entraînement : Realistic Vision 5.1
Celui-ci a été ajouté lors des fusions de mai et fait également partie d'une fusion. Il fonctionne bien avec presque tous les autres modèles réalistes. La v6, pour une raison quelconque, ne fonctionne pas aussi bien de la même manière. - Génération : Realistic Vision 5.1, et un img2img avec un denoise de 0.1 utilisant PicX Real 1.0. RV seul fait le travail, mais j'ai aimé cette combinaison.
Pour SD 1.5 Anime :
- Entraînement : AnyLora
C'est un classique pour l'entraînement. - Génération : Azure Anime v5
Pour SDXL globalement (inclure Pony et Illustrious ici) :
- Entraînement : Modèle de base SDXL
- Génération : Dreamshaper XL Turbo. J'utilise 7 étapes, puis je fais un img2img avec le même prompt mais une nouvelle graine, alors le résultat est sympa !
Pour FLUX globalement :
- Modèle : flux1-Dev-Fp8.safetensors (fichier de 11,1 Go)
- VAE : ae.safetensors
- Clip : clip_l.safetensors
- T5 Encoder : t5xxl_fp8_e4m3fn.safetensors
- 16 Go de Vram nécessaires. Mais vous pouvez essayer cet autre article ici.
Outils que j'utilise
- Pour l'entraînement, vous devez installer : Kohya_ss
Mais parfois, je fais juste tourner un script que j'ai créé pour accélérer le processus, il appelle les scripts Kohya avec tous les paramètres. J'en parlerai à la fin.
La branche sd3-flux.1 est nécessaire pour Flux. - Génération : InvokeAI
Désolé les gens, j'ai Automatic1111 et ComfyUI ici, mais j'adore InvokeAI. - Lora Metadata Viewer : https://civitai.com/models/249721
Préparation du dataset
C'est la partie la plus importante. Vous devez collecter des images de la personne, de l'objet ou de ce que vous voulez entraîner.
Il y a certaines choses à considérer
- Évitez les images de basse résolution ou pixelisées. Je ne recommande pas d'upscaling.
- Évitez les images trop différentes les unes des autres. Je m'en tiens généralement aux portraits.
- Évitez les images avec trop de maquillage, beaucoup de boucles d'oreilles et de colliers, des poses étranges.
- MAINS. Évitez les images où les mains apparaissent trop dans des positions étranges.
- Je recadre une par une pour m'assurer qu'elles incluent uniquement le sujet à entraîner, en supprimant les logos, d'autres personnes, des espaces gaspillés, etc.
Laissez-moi vous montrer le dataset que j'ai obtenu pour Silvio Santos lora :

Vous pouvez voir qu'il s'agit tous de portraits. Différents arrière-plans et couleurs de vêtements sont un MUST. Des visages regardant dans différentes directions aussi.
Note sur la symétrie
Vérifiez si tous les côtés droit et gauche de la personne sont cohérents. Cela peut ne pas être le cas avec des selfies qui sont généralement inversés.
Le visage humain n'est pas symétrique, donc si vous avez une orientation latérale mixte pendant votre entraînement, le résultat peut être comme ceci :

Veuillez réviser l'orientation de votre dataset entier !!
Si les images de prévisualisation commencent à être toutes les mêmes après un certain temps, cela peut être la raison, car SD essaiera d'apprendre les deux côtés et la différence de symétrie peut provoquer une légère augmentation de la perte sur certaines images inversées, alors l'apprentissage se bloquera sur quelques images.
Nombre d'images
- 5 à 10 : Votre Lora n'aura pas beaucoup de variations, mais peut fonctionner
- 11 à 20 : Bon endroit. Peut générer un bon lora.
- 21 à 50 : Cette large gamme est ce que nous voulons !
- 50 à 100 : Trop, mais fonctionne quand vous voulez ajouter des portraits ET des corps entiers mélangés.
- > 100 : Gaspillage de travail.
Résolution
La résolution peut varier de 256x à 2048x. Évitez les images en dessous ou au-dessus de ces valeurs. Vous n'avez pas besoin de redimensionner si elles sont dans ces valeurs, car l'entraînement le fera automatiquement dans des buckets :
La structure des dossiers :
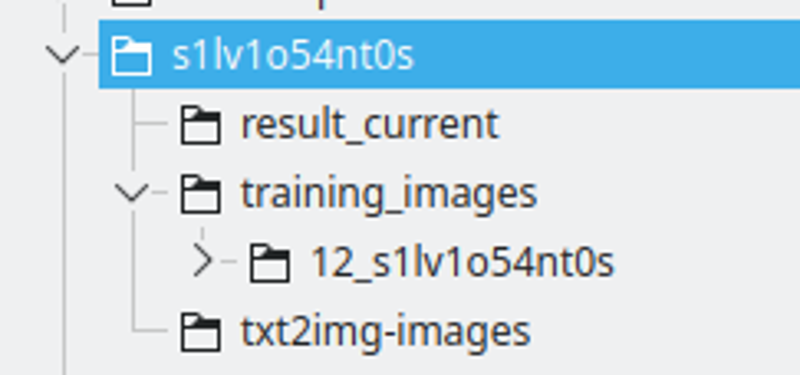
Je crée un dossier avec le nom de la chaîne LoRA. Je nomme la chaîne en remplaçant certaines lettres par des chiffres, pour m'assurer qu'il s'agira d'un token unique à travers de nombreux modèles.
Le result_current sera l'endroit où Kohya enregistrera les résultats
Les images d'entraînement auront le répertoire contenant les images d'entraînement. La convention de nommage est : 400 / nombre d'images, un underscore et la chaîne lora. Ce sera le nombre de répétitions que Kohya effectuera. Je trouve ce nombre un bon endroit pour avoir un bon intervalle entre les époques.
txt2img-images est l'endroit où je stocke les images générées en utilisant le LoRA - Optionnel.
Légendage
C'est le processus où vous allez décrire ce que chaque image est, alors SD saura comment utiliser le modèle existant pour construire les images d'entraînement à partir du bruit.
Dans Kohya, dans l'onglet utilitaires, nous avons le légendage Blip. J'utilise cela avec ces configurations :
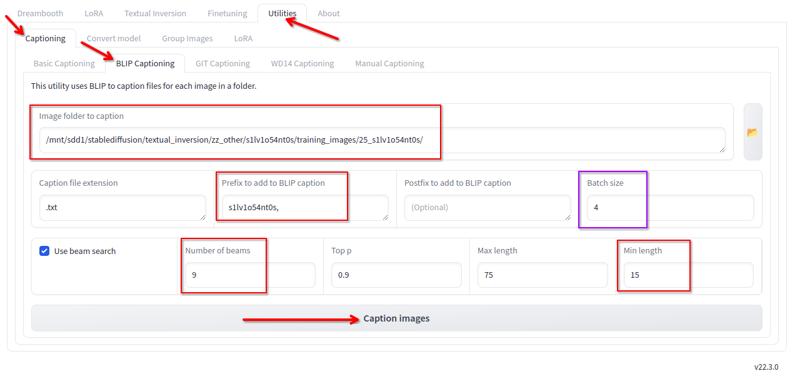
Je change les éléments suivants :
- Dossier où se trouvent les images.
- Le préfixe est le nom de la lora et une virgule
- Nombre de faisceaux 9
- Longueur min 15
- Taille de lot 4
- Tous les autres valeurs, je les garde par défaut.
Cliquez sur légender et cela générera, après un certain temps, les légendes :
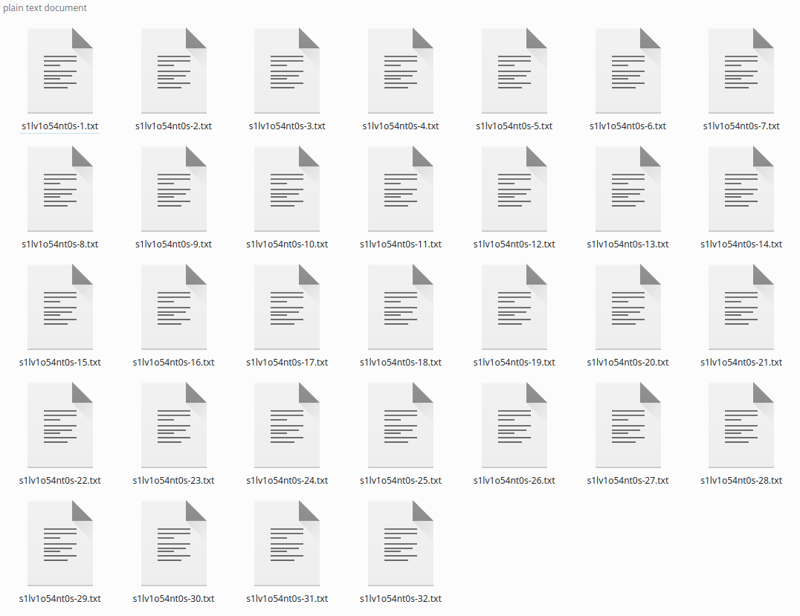
Si vous avez peu d'images, vous pouvez corriger les légendes, car Blip ADORE ajouter des phrases comme « tenant une télécommande » ou « avec un microphone à la main » qui ne sont pas vraies. Je les ignore et cela fonctionne ainsi, car le légendage global est bon.
*Vous pourriez dire que ce légendage « basique » n'est pas bon pour Flux, qu'un meilleur légendage utilisant LLM est mieux, mais cela fonctionne bien pour moi.
Dossier de régularisation
Dans le passé, pour les premiers loras que j'ai publiés, j'ai utilisé un dossier de régularisation avec plus de 4K images de femmes. J'ai arrêté de l'utiliser car il n'est requis que lorsque votre dataset n'est pas légendé et plus varié.
Son utilisation doublera le temps et les étapes nécessaires.
Ne pas utiliser.
Lancer l'entraînement
Ici, nous allons lancer l'entraînement. Pour SD1.5, ces configurations nécessitent 8 Go de Vram, SDXL nécessite 10 Go de Vram, Flux nécessite 16 Go de Vram.
L'installation de Kohya dépasse le cadre de ce guide.
Configurations Kohya
Configs SD1.5 : https://jsonformatter.org/a3213d
Configs SDXL : https://jsonformatter.org/66e5c8
Configs FLUX : https://jsonformatter.org/45c1fc
* Faites-moi savoir si les liens expirent
* Pour FLUX, je limite l'entraînement à 1800 étapes (déjà dans le fichier de configuration ci-dessus) mais autour de 1200 étapes, le LoRA est déjà bon.
* Également pour FLUX, mes paramètres ci-dessus ne convergaient pas l'entraînement pour les ANIMES et les CARTOONS. Donc, vous devrez peut-être augmenter le –learning_rate=0.0004 –unet_lr=0.0004 à 0.001 ou 0.002. Avec cela, l'entraînement devient bon en moins d'étapes, mais peut surajuster plus facilement.
Il suffit de charger ces fichiers dans l'onglet Kohya LORA — PAS L'ONGLET DREAMBOOT — cliquez sur le fichier de configuration et chargez-le.
Les configs que vous DEVEZ changer :
Section Modèle et Dossiers :
- Dossier d'images – le dossier training_images que nous avons créé précédemment. PAS le dossier avec le numéro, le dossier parent.
- Dossier de sortie – le dossier result_current que nous avons créé précédemment
- Nommeur de sortie – le nom de la chaîne de la lora
Onglet Paramètres > Avancé > Échantillons :
- Changez le prompt. Il doit être simple, il sera utilisé pour générer les images d'échantillon. Gardez-le simple
Onglet Paramètres > Basique :
- Vous pouvez changer le nombre d'époques, mais je garderais 6 pour commencer.
Recherchez sur Internet ce que signifie chaque champ, il est hors de portée pour expliquer tous, mais vous pouvez lire ici : Paramètres d'entraînement LoRA
Utilisation du matériel
La plupart des configurations changent les exigences matérielles.
Ceux-ci sont ceux qui ont fonctionné pour moi, utilisant une RTX2060 super avec 12 Go de Vram — Pour FLUX, j'ai mis à niveau vers une RTX 4060 TI 16 Go de Vram.
Par exemple, ma RTX2060 ne prend pas en charge bf16 comme les 3060, donc j'utilise fp16. Cela me ferait économiser de la mémoire, mais c'est ce que c'est et avec 12 Go, cela a fonctionné.
Après avoir changé tout cela, cliquez sur « Commencer l'entraînement ». Vous verrez ceci dans la console :
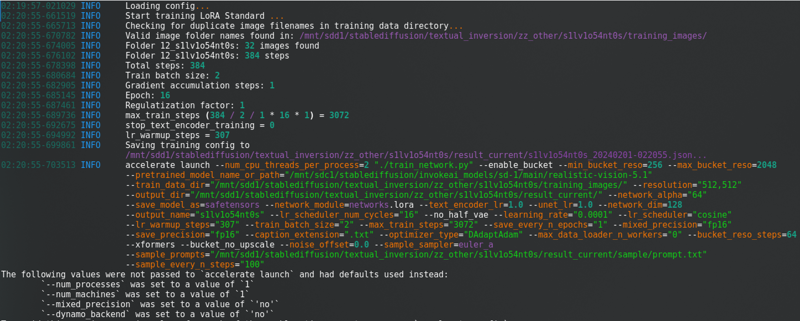
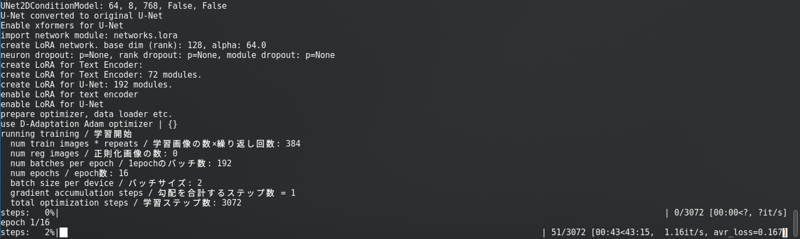
Avec une longue barre de progression.
SD1.5 : Je ne mets pas en cache les latents sur le disque. C'est plus rapide, mais utilise presque la même Vram que SDXL.
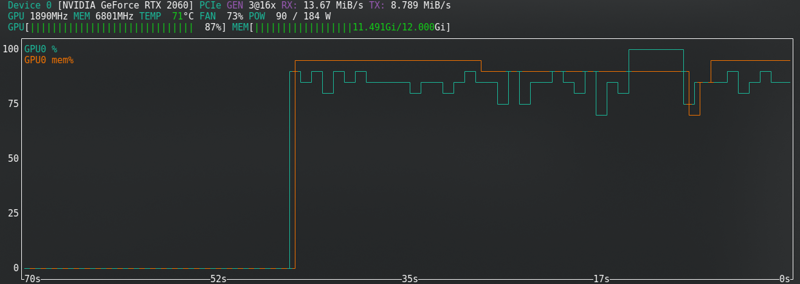

SDXL :
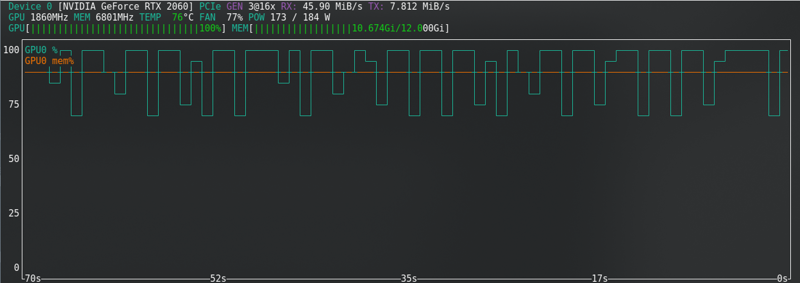

FLUX : Près de la limite même avec la nouvelle carte !!!!!
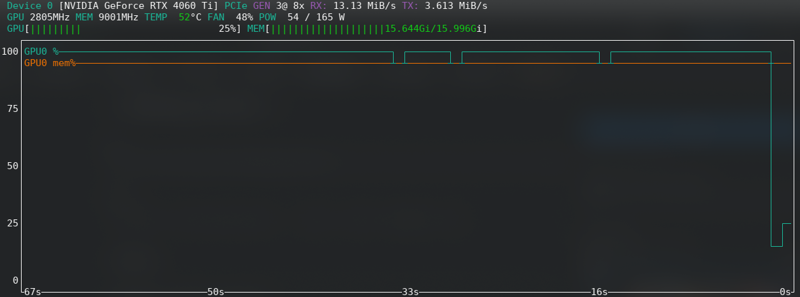
Erreur de mémoire insuffisante
Si vous recevez des erreurs CUDA de mémoire insuffisante, alors vous êtes à la limite. Activez le cache des latents sur le disque, changez de fp16 à bf16 si votre matériel le prend en charge, réduisez la taille du lot de 2 à 1.
Pour Flux, vous pouvez activer le « mode fractionné ». Cela réduit beaucoup de VRAM, mais double presque le temps d'entraînement.
D'autres options sont : Fermez tous les programmes, déconnectez votre 2ème moniteur, réduisez la résolution d'affichage, si vous êtes sous Linux, changez temporairement pour un environnement de bureau plus léger, une fois l'entraînement déclenché, fermez le navigateur et vérifiez l'état uniquement avec l'invite de commande ouverte.
Si vous ne pouvez pas le résoudre, recherchez sur Internet. Si vous obtenez toujours des erreurs, alors abandonnez et entraînez dans CivitAI.
Aperçu de l'entraînement
Les résultats s'amélioreront avec le temps à mesure qu'il apprend.

Résultats de l'entraînement
Lorsque cela se termine, le répertoire ressemblera à cela :
Vous pouvez vérifier par les images d'échantillon si c'est surentraîné ou sous-entraîné. Vous le verrez également en exécutant le LoRA.
Surentraîné
Si le modèle est surentraîné, les images seront « pixelisées comme de l'argile »... Je ne sais pas comment décrire. Les images de prévisualisation commenceront à se déformer.
Voyez avec vos yeux, une image générée :

Parfois, il n'obtient pas ce mauvais résultat, mais le visage CESSERA de ressembler à la personne entraînée jusqu'à ce qu'il se déforme dans les époques suivantes.

La solution est simple : Il suffit de tester les époques précédentes et de voir la plus récente qui fonctionne bien. En fonction de l'image d'échantillon, vous pouvez facilement trouver la bonne et trouver le fichier LoRA généré autour du même moment.
C'est DIFFICILE DE CHOISIR UN !!! Mais cela doit être fait. Testez autant que vous le pouvez.
Sous-entraîné
S'il est sous-entraîné (le visage du portrait ne ressemble pas à la personne et semble être un mélange de personnes génériques du modèle SD, ou l'objet n'a pas encore les détails souhaités), vous pouvez reprendre l'entraînement.

Dans cette image d'exemple, vous voyez que des détails manquent, comme le microphone fusionnant avec la cravate.
La différence avec le surentraînement est le manque de détail.
Si vous avez fermé Kohya, pas de problème, il suffit de charger le json qu'il crée dans le répertoire de résultats et toutes les configurations utilisées seront chargées.
Dans Paramètres > Basique, vous avez le champ Poids du réseau LoRA où vous pouvez ajouter n'importe quel lora que vous souhaitez continuer à entraîner.
Renommez le dernier que vous avez obtenu à un autre nom, copiez son emplacement dans ce champ, changez les époques à 2 ou 3 (cela dépend de combien vous aurez besoin de continuer l'entraînement) et cliquez à nouveau sur commencer l'entraînement. Cela reprendra l'entraînement.
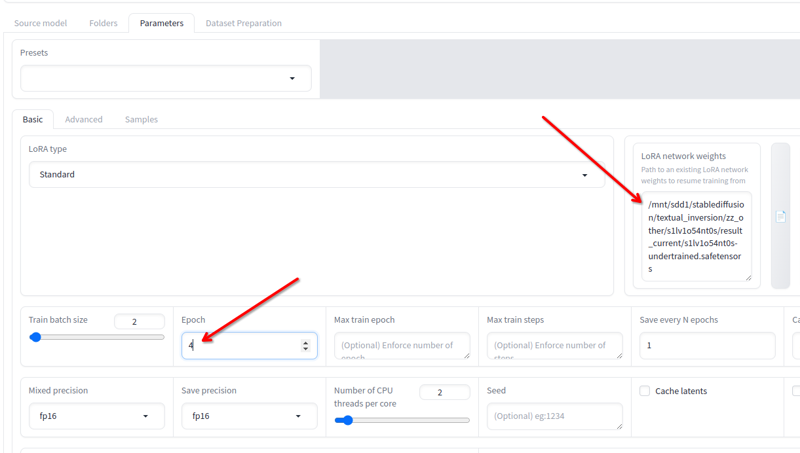
Vous pouvez faire cela jusqu'à ce que ce soit bon !
Terminé !
Renommez l'époques finale de lora que vous souhaitez (ou gardez-la si le résultat final est bon) et utilisez-la.
Ceci est l'exemple SD1.5 :

Ceci est l'exemple Flux :






