
NSFW LoRAのトレーニング方法(FLUX対応版)
g
By gerogero
Updated: March 13, 2026
トレーニングに使用するモデル
SD 1.5 リアルな写真の場合:
- トレーニング: Realistic Vision 5.1
これは5月のマージで追加され、他のほとんどのリアルなモデルともうまく機能します。理由は不明ですが、v6は同じようにうまく機能しません。 - 生成: Realistic Vision 5.1、および PicX Real 1.0を使用したデノイズ0.1のimg2img。RV単独でも機能しますが、この組み合わせが気に入りました。
SD 1.5 アニメの場合:
- トレーニング: AnyLora
これはトレーニング用の定番です。 - 生成: Azure Anime v5
SDXL 全体(ここにPonyとIllustriousを含む):
- トレーニング: SDXL Base model
- 生成: Dreamshaper XL Turbo。私は7ステップを使用し、同じプロンプトで新しいシードを使ったimg2imgを行います。すると、結果が素晴らしいです!
FLUX 全体の場合:
- モデル: flux1-Dev-Fp8.safetensors (11.1 GBファイル)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 Encoder: t5xxl_fp8_e4m3fn.safetensors
- 16GbのVramが必要です。しかし、こちらの他の記事を試してみてください。
私が使用するツール
- トレーニングにはインストールが必要です: Kohya_ss
ただし、時々プロセスを加速するために自分で作ったスクリプトを実行します。これはすべてのパラメータを持つKohyaスクリプトを呼び出します。最後にそれについて話します。
Fluxにはsd3-flux.1ブランチが必要です。 - 生成: InvokeAI
ごめんなさい、ここにはAutomatic1111とComfyUIがありますが、私はInvokeAIが大好きです。 - Loraメタデータビューア: https://civitai.com/models/249721
データセットの準備
これは最も重要な部分です。トレーニングしたい人物、物体、またはその他の画像を収集する必要があります。
考慮すべき点
- 低解像度やピクセル化された画像は避けてください。アップスケーリングはお勧めしません。
- あまりにも異なる画像は避けてください。私は通常、ポートレートにこだわります。
- メイクが多すぎる画像、たくさんのイヤリングやネックレス、奇妙なポーズは避けてください。
- 手。手が奇妙な位置に現れる画像は避けてください。
- ロゴや他の人、無駄なスペースを取り除き、トレーニング対象のみを含むように一つずつトリミングします。
私が収集したデータセットを Silvio Santos loraのためにお見せします:

すべてポートレートであることがわかります。異なる背景や服の色が必要です。顔が異なる方向を向いていることも重要です。
対称性についての注意
すべての画像で人物の右側と左側が一貫しているか確認してください。これは通常、反転している自撮りには当てはまらないかもしれません。
人間の顔は対称ではありません。したがって、トレーニング中に混合された側の向きがある場合、結果は次のようになる可能性があります:

データセット全体の向きを確認してください!!
しばらくしてプレビュー画像がすべて同じになる場合、これが理由かもしれません。SDは両側を学習しようとし、対称性の違いが一部の反転画像でロスを少し高くする可能性があるため、学習がいくつかの画像に固まってしまいます。
画像の数
- 5から10: あなたのLoraはあまり変化がありませんが、機能する可能性があります。
- 11から20: 良い範囲です。良いLoraを生成できます。
- 21から50: この広い範囲が望ましいです!
- 50から100: 多すぎますが、ポートレートと全身を混ぜて追加したい場合に機能します。
- 100以上: 労力の無駄です。
解像度
解像度は256xから2048xまで変わることがあります。これらの値以下または以上の画像は避けてください。これらの値内にある場合はリサイズする必要はありません。トレーニングが自動的にバケット内で行います:
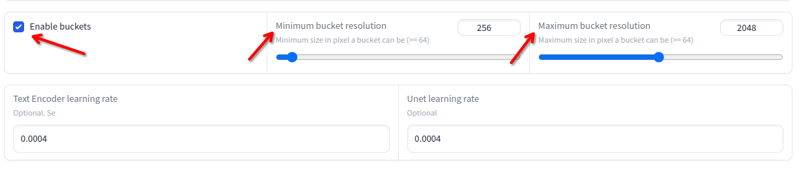
フォルダー構造:
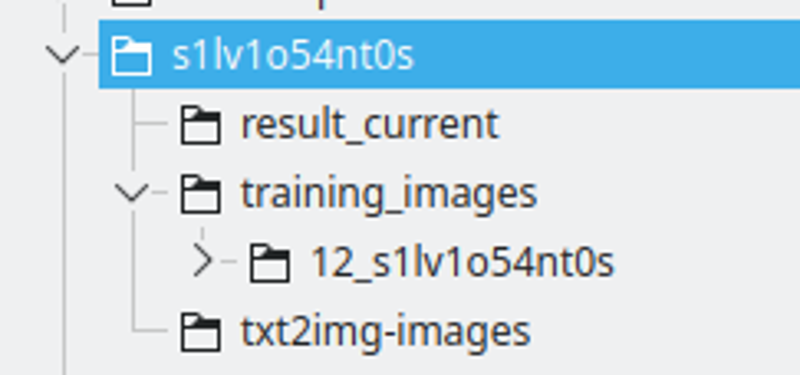
LoRAの文字列名でフォルダーを作成します。文字列の一部の文字を数字に置き換えて、さまざまなモデル間でユニークなトークンになるようにします。
result_currentはKohyaが結果を保存する場所になります。
トレーニング画像はトレーニング画像を含むディレクトリを持ちます。 名前の規則 は: 400 / 画像の数、アンダースコアとloraの文字列です。これはKohyaが行う繰り返しの数になります。この数はエポック間の良い間隔を持つための良い場所だと思います。
txt2img-imagesはLoRAを使用して生成した画像を保存する場所です - オプション。
キャプショニング
これは各画像が何であるかを説明するプロセスです。これにより、SDはノイズからトレーニング画像を構築するために既存のモデルをどのように使用するかを知ります。
KohyaのユーティリティタブにはBlipキャプショニングがあります。私はこれを次の設定で使用します:
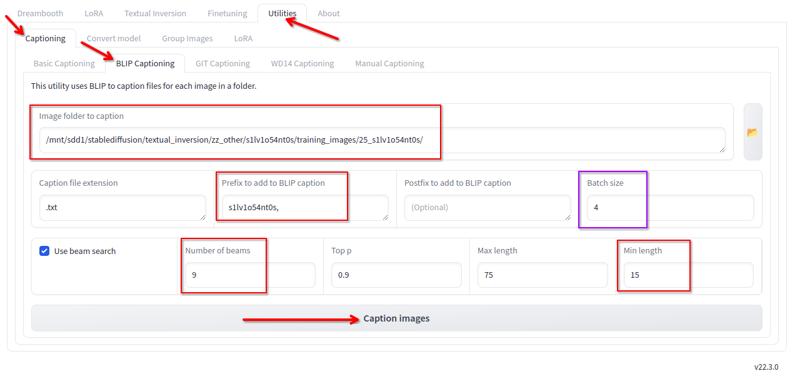
次の変更を行います:
- 画像があるフォルダー。
- プレフィックスはloraの名前とカンマです。
- ビーム数は9です。
- 最小長さは15です。
- バッチサイズは4です。
- 他のすべての値はデフォルトのままにします。
キャプションをクリックすると、しばらくしてキャプションが生成されます:
画像が少ない場合は、キャプションを修正することができます。Blipは「リモコンを持っている」や「手にマイクを持っている」といったフレーズを追加するのが大好きですが、これは真実ではありません。私は無視していますが、全体的なキャプショニングは良好です。
*この「基本的な」キャプショニングがFluxにとって良くないと言うかもしれませんが、LLMを使用したより良いキャプショニングが良いですが、私にはうまく機能しています。
正則化フォルダー
過去に、私が公開した最初のloraのために、4K以上の女性画像を含む正則化フォルダーを使用しました。 使用を中止しました 。これは、データセットがキャプションされておらず、より多様な場合にのみ必要です。
使用すると、必要な時間とステップが倍増します。
使用しないでください。
トレーニングの実行
ここではトレーニングを実行します。SD1.5ではこれらの設定に8GBのVramが必要で、SDXLでは10GBのVramが必要で、Fluxでは16GBのVramが必要です。
Kohyaのインストールはこのガイドの範囲を超えています。
Kohyaの設定
SD1.5の設定: https://jsonformatter.org/a3213d
SDXLの設定: https://jsonformatter.org/66e5c8
FLUXの設定: https://jsonformatter.org/45c1fc
* リンクが期限切れの場合はお知らせください
* FLUXについては、トレーニングを1800ステップに制限しています(上記の設定ファイルに既に含まれています)が、約 1200 ステップでLoRAはすでに良好です。
* また、FLUXについては、上記の設定ではアニメや漫画のトレーニングが収束していませんでした。したがって、–learning_rate=0.0004 –unet_lr=0.0004を0.001または0.002に増やす必要があるかもしれません。これにより、トレーニングが少ないステップで良好になりますが、オーバーフィットしやすくなる可能性があります。
これらのファイルをKohyaのLORAタブ — 夢のブートタブではありません —に読み込みます。設定ファイルをクリックして読み込みます。
変更が必要な設定:
モデルとフォルダーのセクション:
- 画像フォルダー - 前に作成したtraining_imagesフォルダー。番号の付いたフォルダーではなく、親フォルダーです。
- 出力フォルダー - 前に作成したresult_currentフォルダー
- 出力名 - loraの文字列名
パラメータタブ > 高度な設定 > サンプル:
- プロンプトを変更します。シンプルでなければなりません。サンプル画像を生成するために使用されます。シンプルに保ってください。
パラメータタブ > 基本:
- エポック数を変更できますが、最初は6を維持することをお勧めします。
各フィールドの意味についてインターネットで調べてください。すべてを説明するのは今のところ範囲外ですが、こちらを読んでください: LoRAトレーニングパラメータ
ハードウェアの利用
ほとんどの設定はハードウェアの要件を変更します。
これらは私にとって機能した設定です。RTX2060スーパーで12GBのVramを使用しています — FLUXのためにRTX 4060 TI 16GB Vramにアップグレードしました。
例えば、私のRTX2060は3060のようにbf16をサポートしていないため、fp16を使用しています。これによりメモリを節約できますが、12Gで機能しています。
すべてを変更したら、「トレーニングを開始」をクリックします。コンソールに次のように表示されます:
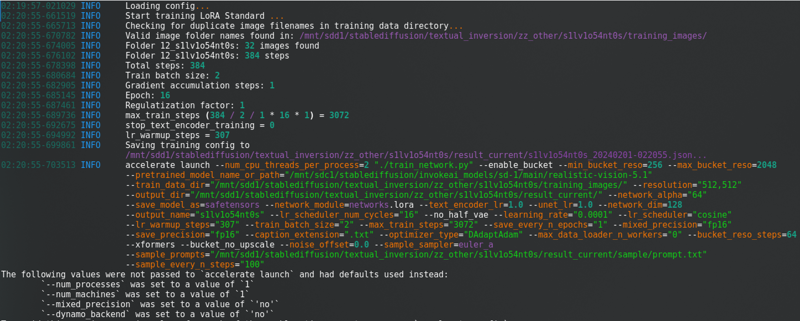
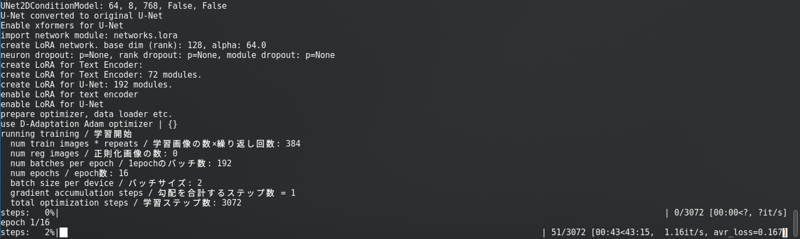
長いプログレスバーが表示されます。
SD1.5: ラテントをディスクにキャッシュしません。速いですが、SDXLとほぼ同じVramを使用します。
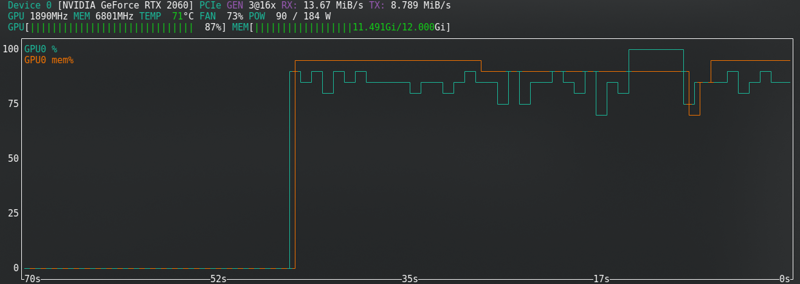

SDXL:
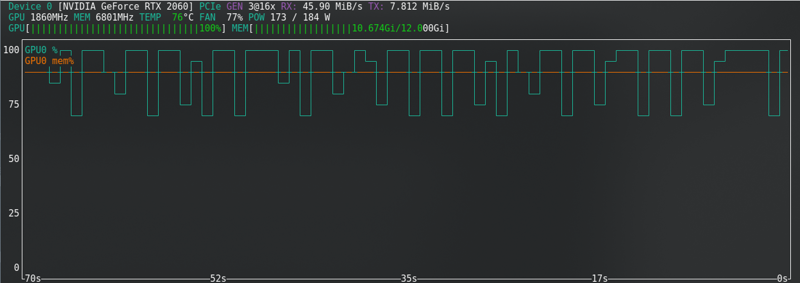

FLUX: 新しいカードでも限界に近い!!!!!
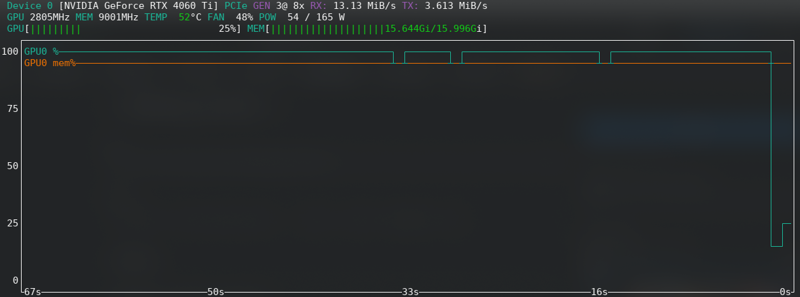
メモリエラー
CUDAのメモリ不足エラーが発生した場合、限界に達しています。ラテントをディスクにキャッシュを有効にし、ハードウェアがサポートしている場合はfp16からbf16に変更し、バッチサイズを2から1に減らしてください。
Fluxの場合、「スプリットモード」を有効にできます。これによりVRAMが大幅に削減されますが、トレーニング時間がほぼ倍増します。
他のオプションは: すべてのプログラムを閉じる、2番目のモニターを切断する、ディスプレイ解像度を下げる、Linuxの場合は軽量のデスクトップ環境に一時的に変更する、トレーニングを開始したらブラウザを閉じてコマンドプロンプトを開いたままステータスを確認することです。
解決できない場合は、インターネットで検索してください。まだエラーが発生する場合は、あきらめてCivitAIでトレーニングしてください。
トレーニングプレビュー
100ステップごとに(変更可能)、トレーニングはresults_current/sampleフォルダーにサンプル画像を作成します。これにより、機能しているかどうかのアイデアが得られます。
結果は、学習が進むにつれて改善されます。

トレーニング結果
終了すると、ディレクトリは次のようになります:
サンプル画像を確認することで、過剰にトレーニングされたか、過少にトレーニングされたかを確認できます。LoRAを実行するときにもそれがわかります。
過剰にトレーニングされた
モデルが過剰にトレーニングされている場合、画像は「粘土でできたピクセル化されたもの」になります...どう説明すればいいかわかりません。プレビュー画像が歪み始めます。
生成された画像を目で確認してください:

時々、これほど悪い結果にはなりませんが、顔はトレーニングされた人物のように見えなくなり、後のエポックで変形するまでそのままになります。

解決策は簡単です: 前のエポックをテストして、うまく機能している最新のものを見つけてください。サンプル画像に基づいて、良いものを簡単に見つけ、同じ時期に生成されたLoRAファイルを見つけることができます。
選ぶのは難しいですが、必ず行ってください。できるだけ多くテストしてください。
過少にトレーニングされた
過少にトレーニングされている場合(ポートレートの顔が人物に似ておらず、SDモデルの一般的な人物のミックスのように見える、またはオブジェクトに望ましい詳細がまだない場合)、トレーニングを再開できます。

この例の画像では、マイクがネクタイと合体しているように、詳細が欠けています。
過剰にトレーニングされた場合との違いは、詳細が不足していることです。
Kohyaを閉じた場合でも問題ありません。結果ディレクトリに作成されるjsonを読み込むと、使用されたすべての設定が読み込まれます。
パラメータ > 基本のフィールドにLoRAネットワークの重み があり、トレーニングを続けたい任意のloraを追加できます。
最後のものを別の名前に変更し、その場所をこのフィールドにコピーし、エポックを2または3に変更(どれだけトレーニングを続ける必要があるかによります)して、再度トレーニングを開始 をクリックします。トレーニングが再開されます。
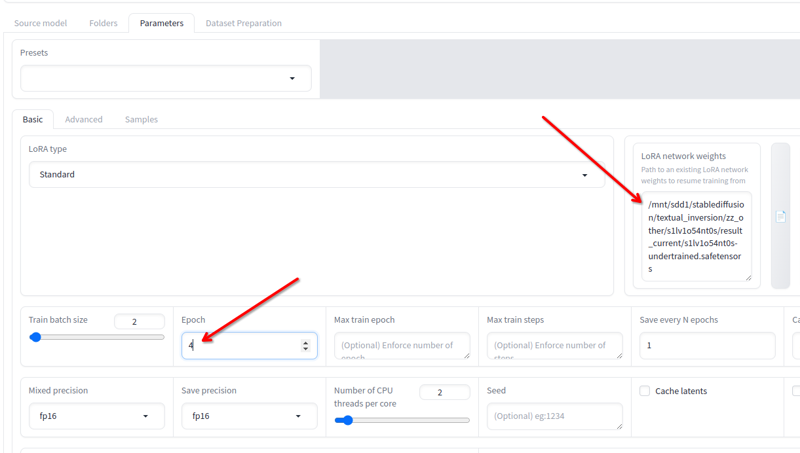
それが良くなるまで続けることができます!
完了!
最終的なloraエポックの名前を変更するか(または最終結果が良ければそのままにします)使用します。
これは SD1.5の例:

これは Fluxの例:






