Latihan: Realistic Vision 5.1 Ini ditambahkan pada penggabungan bulan Mei dan juga merupakan bagian dari penggabungan. Kemudian berfungsi baik dengan hampir semua model realistik lainnya. Versi v6 entah kenapa tidak berfungsi dengan baik dengan cara yang sama.
Generasi: Realistic Vision 5.1, dan img2img dengan denoise 0.1 menggunakan PicX Real 1.0. RV sendiri sudah cukup, tetapi saya suka kombinasi ini.
Generasi: Dreamshaper XL Turbo. Saya menggunakan 7 langkah, dan kemudian saya melakukan img2img dengan prompt yang sama tetapi seed baru, kemudian hasilnya bagus!
Untuk latihan anda perlu memasang: Kohya_ss Tetapi kadang-kadang saya hanya menjalankan skrip yang saya buat untuk mempercepat proses, ia memanggil skrip Kohya dengan semua parameter. Saya akan bercakap tentangnya di akhir. Cabang sd3-flux.1 diperlukan untuk Flux.
Generasi: InvokeAI Maaf semua, saya ada Automatic1111 dan ComfyUI di sini, tetapi saya suka InvokeAI.
Ini adalah bahagian yang paling penting. Anda perlu mengumpul gambar dari orang, objek atau apa sahaja yang anda ingin latih.
Ada beberapa perkara yang perlu dipertimbangkan
Elakkan resolusi rendah atau gambar yang berpiksel. Saya tidak mengesyorkan memperbesar.
Elakkan gambar yang terlalu berbeza antara satu sama lain. Saya biasanya fokus pada potret.
Elakkan gambar dengan terlalu banyak solekan, banyak anting-anting dan kalung, pose yang aneh.
TANGAN. Elakkan gambar di mana tangan muncul terlalu banyak dalam posisi yang aneh.
Saya memotong satu persatu untuk memastikan mereka hanya termasuk subjek yang ingin dilatih, mengeluarkan logo, orang lain, ruang yang terbuang, dsb.
Biarkan saya menunjukkan dataset yang saya dapat untuk Silvio Santos lora:
Anda boleh melihat bahawa semuanya adalah potret. Latar belakang dan warna pakaian yang berbeza adalah MESTI. Wajah yang menghadap ke arah yang berbeza juga.
Nota tentang simetri
Periksa jika semua gambar sisi kanan dan kiri orang adalah konsisten. Ini mungkin tidak berlaku dengan selfie yang biasanya terbalik.
Wajah manusia tidak simetri, jadi jika anda mempunyai orientasi sisi campuran semasa latihan anda, hasilnya mungkin seperti ini:
Sila semak orientasi seluruh dataset anda!!
Jika gambar pratonton selepas beberapa ketika mula menjadi semua sama, ini mungkin sebabnya, kerana SD akan cuba belajar kedua-dua sisi dan perbezaan dalam simetri mungkin menyebabkan kehilangan sedikit lebih tinggi dalam beberapa gambar yang terbalik, kemudian pembelajaran akan terhenti pada beberapa gambar sahaja.
Bilangan gambar
5 hingga 10: Lora anda tidak akan mempunyai banyak variasi, tetapi boleh berfungsi
11 hingga 20: Tempat yang baik. Boleh menghasilkan lora yang baik.
21 hingga 50: Julat luas ini adalah apa yang kita mahu!
50 hingga 100: Terlalu banyak, tetapi berfungsi apabila anda ingin menambah potret DAN campuran badan penuh.
> 100: Pembaziran kerja.
Resolusi
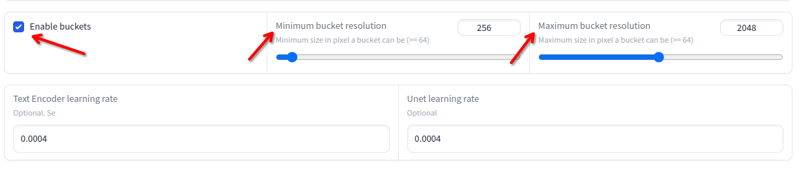
Resolusi boleh berbeza dari 256x hingga 2048x. Elakkan gambar di bawah atau di atas nilai ini. Anda tidak perlu mengubah saiz jika ia berada dalam nilai ini, kerana latihan akan melakukannya secara automatik dalam baldi:
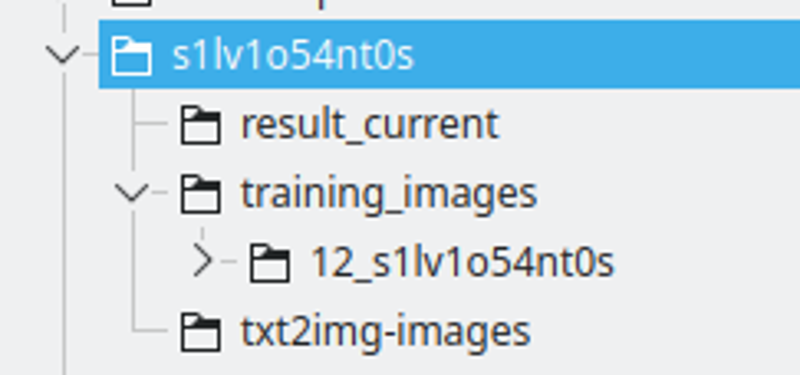
Struktur folder:
Saya membuat folder dengan nama string LoRA. Saya menamakan string dengan menggantikan beberapa huruf dengan nombor, untuk memastikan ia akan menjadi token unik di seluruh banyak model.
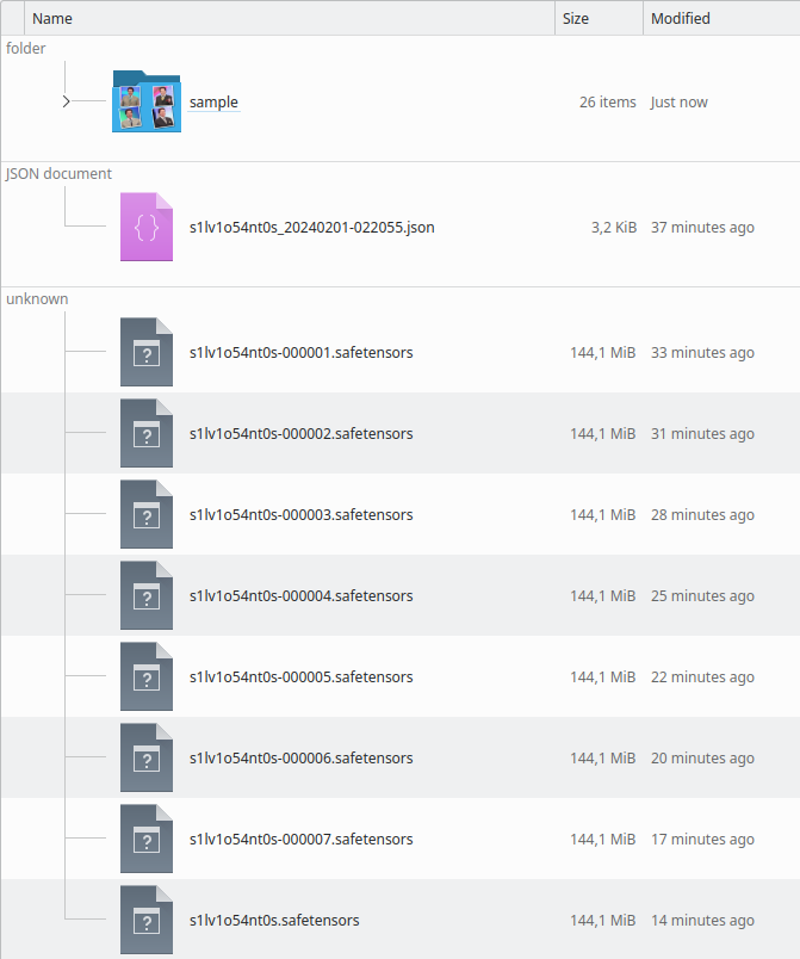
Hasil_current akan menjadi tempat di mana Kohya akan menyimpan hasilnya
Gambar latihan akan mempunyai direktori yang mengandungi gambar latihan. Konvensi nama adalah: 400 / bilangan gambar, garis bawah dan string lora. Ini akan menjadi bilangan pengulangan yang akan dilakukan Kohya. Saya mendapati nombor ini adalah tempat yang baik untuk mempunyai selang yang baik antara epoch.
txt2img-images adalah di mana saya menyimpan gambar yang dihasilkan menggunakan LoRA – Pilihan.
Kapsyen
Ini adalah proses di mana anda akan menerangkan apa itu setiap gambar, kemudian SD akan tahu bagaimana menggunakan model yang ada untuk membina gambar latihan dari bunyi.
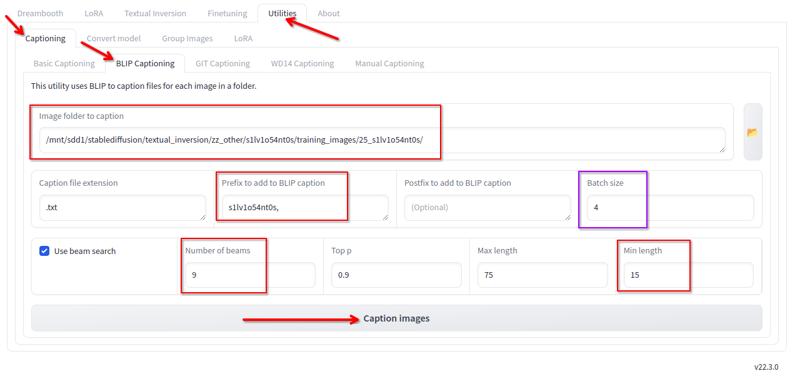
Dalam Kohya, di tab utiliti, kita mempunyai kapsyen Blip. Saya menggunakan ini dengan konfigurasi berikut:
Saya mengubah yang berikut:
Folder di mana gambar berada.
Prefiks adalah nama lora dan koma
Bilangan sinar 9
Panjang min 15
Saiz batch 4
Semua nilai lain saya biarkan sebagai lalai.
Klik pada kapsyen dan ia akan, selepas beberapa ketika, menjana kapsyen:
Jika anda mempunyai sedikit gambar, anda mungkin perlu memperbaiki kapsyen, kerana Blip SANGAT suka menambah frasa seperti “memegang alat kawalan jauh” atau “Dengan mikrofon di tangan” yang tidak benar. Saya hanya mengabaikan dan ia telah berfungsi dengan baik, kerana keseluruhan kapsyen adalah baik.
*Anda mungkin mengatakan bahawa kapsyen “asas” ini tidak baik untuk Flux, bahawa kapsyen yang lebih baik menggunakan LLM adalah lebih baik, tetapi ia telah berfungsi dengan baik untuk saya.
Folder regularisasi
Di masa lalu, untuk lora pertama yang saya terbitkan, saya menggunakan folder regularisasi dengan lebih daripada 4K gambar wanita. Saya berhenti menggunakannya kerana ia hanya diperlukan apabila dataset anda tidak diberi kapsyen dan lebih bervariasi.
Menggunakannya akan menggandakan masa dan langkah yang diperlukan.
Jangan gunakan.
Menjalankan latihan
Di sini kita akan menjalankan latihan. Untuk SD1.5 konfigurasi ini memerlukan 8GB Vram, SDXL memerlukan 10GB Vram, Flux memerlukan 16GB Vram.
* Untuk FLUX, saya menghadkan latihan kepada 1800 langkah (sudah ada dalam fail konfigurasi di atas) tetapi sekitar 1200 langkah LoRA sudah baik.
* Juga untuk FLUX, tetapan saya di atas tidak mengkonvergensi latihan untuk ANIMES dan CARTOONS. Jadi, anda mungkin perlu meningkatkan –learning_rate=0.0004 –unet_lr=0.0004 kepada 0.001 atau 0.002. Dengan itu latihan menjadi baik dalam langkah yang lebih sedikit, tetapi mungkin lebih mudah untuk overfit.
Hanya muatkan fail ini dalam tab Kohya LORA — BUKAN TAB DREAMBOOT — klik pada fail konfigurasi dan muatkannya.
Konfigurasi yang PERLU anda ubah:
Bahagian Model dan Folder:
Folder gambar – folder training_images yang kita buat sebelum ini. BUKAN folder dengan nombor, folder induk.
Folder output – folder result_current yang kita buat sebelum ini
Pemberi nama output – nama string lora
Tab Parameter > Lanjutan > Sampel:
Ubah prompt. Ia mesti ringkas, ia akan digunakan untuk menjana gambar sampel. Kekalkan ia ringkas
Tab Parameter > Asas:
Anda boleh mengubah bilangan epoch, tetapi saya akan mengekalkan 6 untuk memulakan.
Cari di internet tentang apa maksud setiap medan, ia di luar skop untuk menerangkan semuanya sekarang, tetapi anda boleh membaca di sini: Parameter latihan LoRA
Penggunaan perkakasan
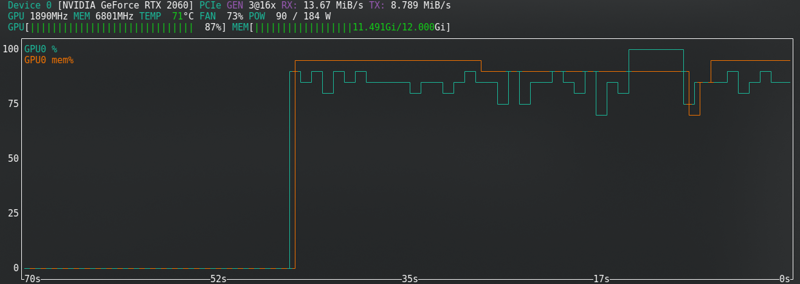
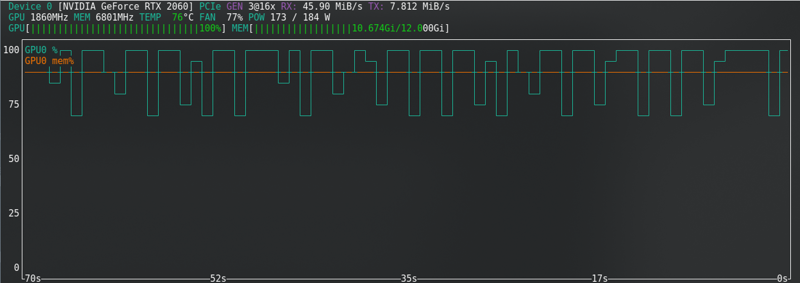
Kebanyakan konfigurasi mengubah keperluan perkakasan.
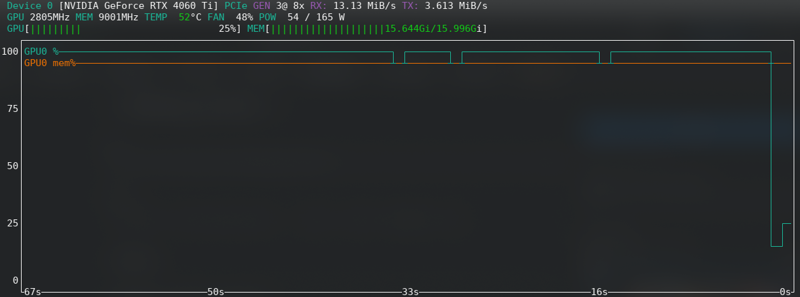
Ini adalah yang berfungsi untuk saya, menggunakan RTX2060 super dengan 12GB Vram — Untuk FLUX saya telah menaik taraf kepada RTX 4060 TI 16GB Vram.
Sebagai contoh, RTX2060 saya tidak menyokong bf16 seperti 3060s, jadi saya menggunakan fp16. Ini akan menjimatkan memori, tetapi ia adalah apa adanya dan dengan 12G telah berfungsi.
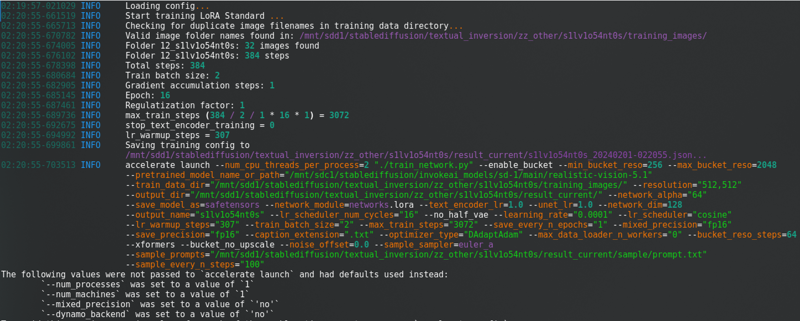
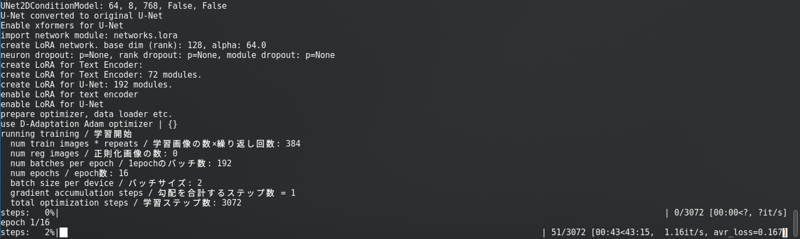
Setelah mengubah semua itu, klik pada “Mulakan latihan“. Anda akan melihat ini di konsol:
Dengan bar kemajuan yang sangat panjang.
SD1.5: Saya tidak menyimpan latents ke disk. Ia lebih cepat, tetapi menggunakan hampir sama Vram seperti SDXL.
SDXL:
FLUX: Hampir mencapai had walaupun dengan kad baru!!!!!
Ralat kehabisan memori
Jika anda menerima ralat CUDA kehabisan memori, maka anda sudah mencapai had. Aktifkan cache latents ke disk, ubah dari fp16 kepada bf16 jika perkakasan anda menyokong, kurangkan Saiz Batch dari 2 kepada 1.
Untuk Flux, anda boleh mengaktifkan “Mod Pisah”. Ini mengurangkan banyak VRAM, tetapi hampir menggandakan masa latihan.
Pilihan lain adalah: Tutup semua program, putuskan sambungan monitor kedua anda, turunkan resolusi paparan, jika di Linux tukar kepada persekitaran desktop yang lebih ringan sementara, setelah memulakan latihan tutup pelayar dan periksa status hanya dengan command prompt dibuka.
Jika anda tidak dapat menyelesaikannya, cari di internet. Jika masih mendapat ralat, maka berputus asa dan latih di CivitAI.
Pratonton latihan
Setiap 100 langkah (anda boleh mengubahnya) latihan akan membuat gambar sampel dalam folder results_current/sample, kemudian anda boleh mendapatkan idea jika ia berfungsi atau tidak.
Hasilnya akan meningkat dari masa ke masa semasa ia belajar.
Hasil latihan
Apabila ia selesai, direktori akan kelihatan seperti ini:
Anda boleh memeriksa melalui gambar sampel jika ia telah dilatih berlebihan atau kurang dilatih. Anda akan melihatnya apabila menjalankan LoRA juga.
Dilatih berlebihan
Jika model dilatih berlebihan, gambar akan menjadi “berpiksel seperti tanah liat”… Saya tidak tahu bagaimana untuk menggambarkannya. Gambar pratonton akan mula terdistorsi.
Lihat dengan mata anda, gambar yang dihasilkan:
Kadang-kadang ia tidak mendapat hasil yang teruk ini, tetapi wajah akan BERHENTI kelihatan seperti orang yang dilatih sehingga ia berubah bentuk dalam epoch yang lebih kemudian.
Penyelesaian adalah mudah: Hanya uji epoch sebelumnya dan lihat yang paling terkini yang berfungsi dengan baik. Berdasarkan gambar sampel anda boleh dengan mudah mencari yang baik dan mencari fail LoRA yang dihasilkan sekitar masa yang sama.
Ia SULIT UNTUK MEMILIH SATU!!! Tetapi mesti dilakukan. Uji sebanyak yang anda boleh.
Kurang dilatih
Jika ia kurang dilatih (Wajah potret tidak kelihatan seperti orang itu dan nampak seperti campuran orang generik dari model SD, atau objek tidak mempunyai butiran yang diingini lagi) anda boleh sambung semula latihan.
Dalam gambar contoh ini anda dapat melihat bahawa butiran hilang, seperti mikrofon yang bercampur dengan tali leher.
Perbezaan dari dilatih berlebihan adalah kekurangan butiran.
Jika anda menutup Kohya, tidak mengapa, hanya muatkan json yang ia buat dalam direktori hasil dan semua konfigurasi yang digunakan akan dimuatkan.
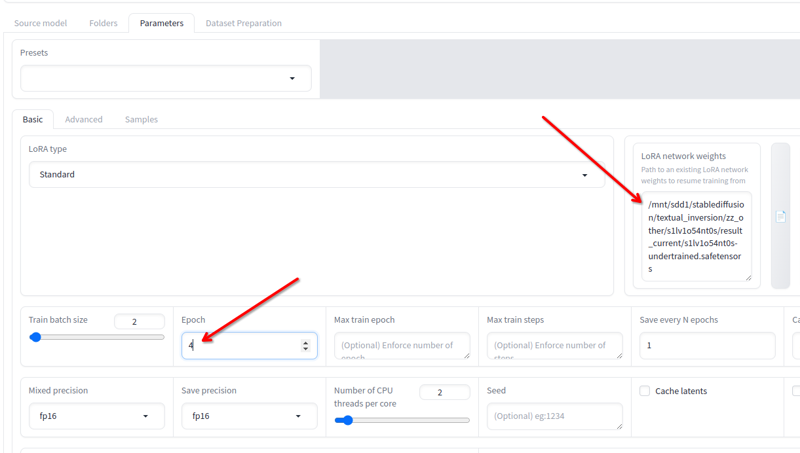
Dalam Parameter > Asas, anda mempunyai medan berat rangkaian LoRA di mana anda boleh menambah mana-mana lora yang anda mahu untuk terus melatih.
Namakan semula yang terakhir anda dapat kepada nama lain, salin lokasi ke medan ini, ubah epoch kepada 2 atau 3 (bergantung kepada berapa banyak yang anda perlukan untuk terus melatih) dan klik pada mulakan latihan sekali lagi. Ia akan menyambung semula latihan.
Anda boleh melakukan itu sehingga ia baik!
Selesai!
Namakan semula epoch lora akhir yang anda mahu (atau simpan jika hasil akhir baik) dan gunakannya.