
Cách huấn luyện NSFW Lora (cập nhật với FLUX)
g
By gerogero
Updated: March 13, 2026
Các mô hình được sử dụng để đào tạo
Đối với SD 1.5 hình ảnh thực tế:
- Đào tạo: Realistic Vision 5.1
Mô hình này được thêm vào trong các lần hợp nhất và cũng là một phần của một lần hợp nhất. Nó hoạt động tốt với hầu hết các mô hình thực tế khác. Phiên bản v6 không hoạt động tốt theo cách tương tự vì một lý do nào đó. - Thế hệ: Realistic Vision 5.1, và một img2img với độ giảm nhiễu 0.1 sử dụng PicX Real 1.0. RV một mình cũng làm tốt công việc, nhưng tôi thích sự kết hợp này.
Đối với SD 1.5 Anime:
- Đào tạo: AnyLora
Mô hình này là một cổ điển cho việc đào tạo. - Thế hệ: Azure Anime v5
Đối với SDXL tổng thể (bao gồm Pony và Illustrious ở đây):
- Đào tạo: Mô hình cơ bản SDXL
- Thế hệ: Dreamshaper XL Turbo. Tôi sử dụng 7 bước, và sau đó tôi thực hiện một img2img với cùng một prompt nhưng với một seed mới, kết quả rất đẹp!
Đối với FLUX tổng thể:
- Mô hình: flux1-Dev-Fp8.safetensors (tệp 11.1 GB)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 Encoder: t5xxl_fp8_e4m3fn.safetensors
- Cần 16Gb Vram. Nhưng bạn có thể thử bài viết khác ở đây.
Các công cụ tôi sử dụng
- Để đào tạo bạn sẽ cần cài đặt: Kohya_ss
Nhưng đôi khi tôi chỉ chạy một script tôi đã tạo để tăng tốc quá trình, nó gọi các script của Kohya với tất cả các tham số. Tôi sẽ nói về điều đó ở cuối.
Nhánh sd3-flux.1 là cần thiết cho Flux. - Thế hệ: InvokeAI
Xin lỗi mọi người, tôi có Automatic1111 và ComfyUI ở đây, nhưng tôi yêu thích InvokeAI. - Trình xem siêu dữ liệu Lora: https://civitai.com/models/249721
Chuẩn bị dữ liệu
Đây là phần quan trọng nhất. Bạn phải thu thập hình ảnh từ người, đối tượng hoặc bất cứ điều gì bạn muốn đào tạo.
Có một số điều cần xem xét
- Tránh hình ảnh có độ phân giải thấp hoặc bị pixel hóa. Tôi không khuyến nghị việc nâng cấp độ phân giải.
- Tránh hình ảnh quá khác nhau. Tôi thường chỉ tập trung vào chân dung.
- Tránh hình ảnh có quá nhiều trang điểm, nhiều hoa tai và dây chuyền, tư thế kỳ lạ.
- ĐÔI BÀN TAY. Tránh hình ảnh mà bàn tay xuất hiện quá nhiều ở các vị trí kỳ lạ.
- Tôi cắt từng cái một để đảm bảo chúng chỉ bao gồm đối tượng cần đào tạo, loại bỏ logo, người khác, không gian lãng phí, v.v.
Để tôi cho bạn xem bộ dữ liệu tôi đã có cho Silvio Santos lora:

Bạn có thể thấy rằng chúng đều là chân dung. Các nền và màu sắc vải khác nhau là điều bắt buộc. Khuôn mặt nhìn về các hướng khác nhau cũng vậy.
Ghi chú về sự đối xứng
Kiểm tra xem tất cả hình ảnh của người đó có hai bên trái và phải đồng nhất hay không. Điều này có thể không đúng với những bức selfie thường bị đảo ngược.
Khuôn mặt con người không đối xứng, vì vậy nếu bạn có sự định hướng bên trái và bên phải trong quá trình đào tạo, kết quả có thể như thế này:

Xin vui lòng xem xét hướng của toàn bộ bộ dữ liệu của bạn!!
Nếu các hình ảnh xem trước sau một thời gian bắt đầu giống nhau, đây có thể là lý do, vì SD sẽ cố gắng học cả hai bên và sự khác biệt trong sự đối xứng có thể khiến mất mát cao hơn một chút trong một số hình ảnh bị đảo ngược, sau đó việc học sẽ bị kẹt trong một vài hình ảnh.
Số lượng hình ảnh
- 5 đến 10: Lora của bạn sẽ không có nhiều biến thể, nhưng có thể hoạt động
- 11 đến 20: Vị trí tốt. Có thể tạo ra một lora tốt.
- 21 đến 50: Phạm vi rộng này là điều chúng ta muốn!
- 50 đến 100: Quá nhiều, nhưng hoạt động khi bạn muốn thêm chân dung VÀ toàn thân trộn lẫn.
- > 100: Lãng phí công sức.
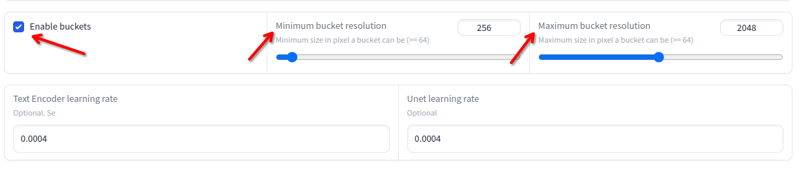
Độ phân giải
Độ phân giải có thể thay đổi từ 256x đến 2048x. Tránh hình ảnh dưới hoặc trên các giá trị này. Bạn không cần phải thay đổi kích thước nếu chúng nằm trong các giá trị này, vì quá trình đào tạo sẽ tự động làm điều đó trong các thùng:
Cấu trúc thư mục:
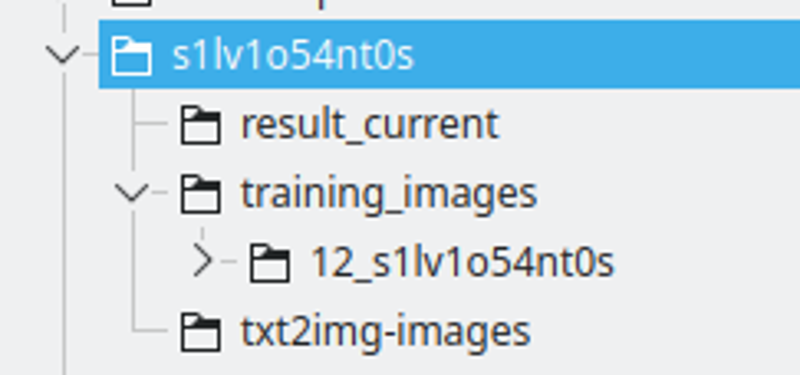
Tôi tạo một thư mục với tên chuỗi LoRA. Tôi đặt tên chuỗi bằng cách thay thế một số chữ cái bằng số, để đảm bảo nó sẽ là một token duy nhất trên nhiều mô hình.
Kết quả_current sẽ là nơi mà Kohya sẽ lưu kết quả
Các hình ảnh đào tạo sẽ có thư mục chứa các hình ảnh đào tạo. Quy ước tên được đặt là: 400 / số lượng hình ảnh, một dấu gạch dưới và chuỗi lora. Đây sẽ là số lần lặp lại mà Kohya sẽ thực hiện. Tôi thấy số này là một vị trí tốt để có khoảng cách tốt giữa các epoch.
txt2img-images là nơi tôi lưu trữ các hình ảnh được tạo ra bằng cách sử dụng LoRA - Tùy chọn.
Chú thích
Đây là quá trình mà bạn sẽ mô tả những gì mỗi hình ảnh là, sau đó SD sẽ biết cách sử dụng mô hình hiện có để xây dựng các hình ảnh đào tạo từ tiếng ồn.
Trong Kohya, trong tab tiện ích, chúng tôi có chú thích Blip. Tôi sử dụng điều này với các cấu hình sau:
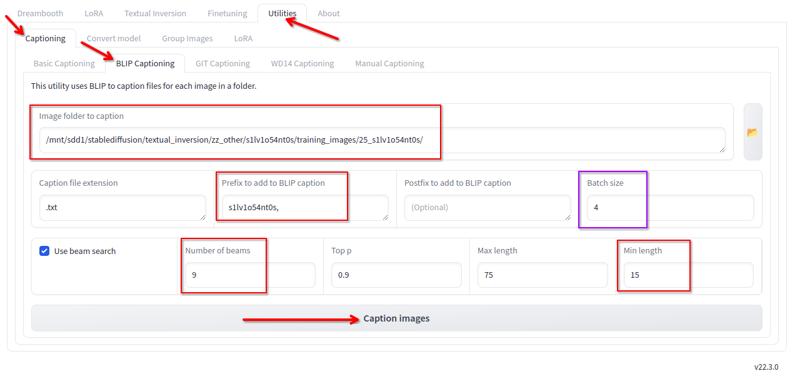
Tôi thay đổi những điều sau:
- Thư mục nơi các hình ảnh nằm.
- Tiền tố là tên lora và một dấu phẩy
- Số lượng beam 9
- Độ dài tối thiểu 15
- Kích thước lô 4
- Tất cả các giá trị khác tôi giữ nguyên mặc định.
Nhấp vào chú thích và sau một thời gian, nó sẽ tạo ra các chú thích:
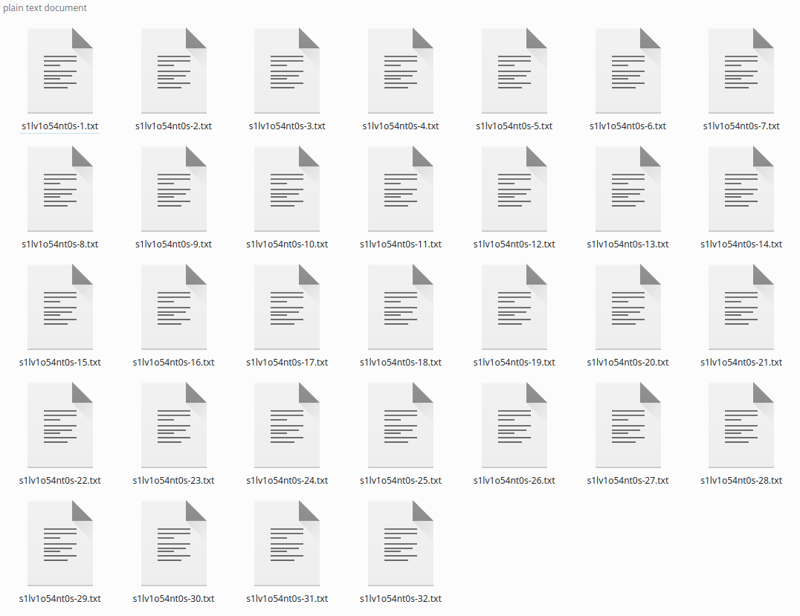
Nếu bạn có ít hình ảnh, bạn có thể sửa các chú thích, vì Blip THÍCH thêm các cụm từ như “cầm điều khiển từ xa” hoặc “Với một chiếc microphone trong tay” mà không đúng sự thật. Tôi chỉ bỏ qua và nó đã hoạt động theo cách đó, vì việc chú thích tổng thể là tốt.
*Bạn có thể nói rằng việc chú thích “cơ bản” này không tốt cho Flux, rằng việc chú thích tốt hơn bằng LLM là tốt hơn, nhưng nó đã hoạt động tốt với tôi.
Thư mục điều chỉnh
Trong quá khứ, cho các lora đầu tiên tôi xuất bản, tôi đã sử dụng một thư mục điều chỉnh với hơn 4K hình ảnh phụ nữ. Tôi đã ngừng sử dụng nó vì nó chỉ cần thiết khi bộ dữ liệu của bạn không được chú thích và đa dạng hơn.
Sử dụng nó sẽ gấp đôi thời gian và số bước cần thiết.
Không sử dụng.
Chạy quá trình đào tạo
Ở đây chúng ta sẽ chạy quá trình đào tạo. Đối với SD1.5, các cấu hình này yêu cầu 8GB Vram, SDXL yêu cầu 10GB Vram, Flux yêu cầu 16GB Vram.
Cài đặt Kohya nằm ngoài phạm vi của hướng dẫn này.
Cấu hình Kohya
Cấu hình SD1.5: https://jsonformatter.org/a3213d
Cấu hình SDXL: https://jsonformatter.org/66e5c8
Cấu hình FLUX: https://jsonformatter.org/45c1fc
* Hãy cho tôi biết nếu các liên kết hết hạn
* Đối với FLUX, tôi đang giới hạn quá trình đào tạo ở 1800 bước (đã có trong tệp cấu hình ở trên) nhưng khoảng 1200 bước thì LoRA đã tốt rồi.
* Cũng đối với FLUX, các cài đặt của tôi ở trên không hội tụ quá trình đào tạo cho ANIMES và CARTOONS. Vì vậy, bạn có thể phải tăng –learning_rate=0.0004 –unet_lr=0.0004 lên 0.001 hoặc 0.002. Với điều đó, quá trình đào tạo trở nên tốt hơn trong ít bước, nhưng có thể dễ dàng bị overfit hơn.
Chỉ cần tải các tệp này vào tab LORA của Kohya — KHÔNG PHẢI TAB DREAMBOOT — nhấp vào tệp cấu hình và tải nó lên.
Các cấu hình bạn PHẢI thay đổi:
Mô hình và phần Thư mục:
- Thư mục hình ảnh – thư mục training_images mà chúng tôi đã tạo trước đó. KHÔNG phải thư mục có số, thư mục cha.
- Thư mục đầu ra – thư mục result_current mà chúng tôi đã tạo trước đó
- Tên đầu ra – tên chuỗi của lora
Tab Tham số > Nâng cao > Mẫu:
- Thay đổi prompt. Nó phải đơn giản, nó sẽ được sử dụng để tạo ra các hình ảnh mẫu. Giữ cho nó đơn giản
Tab Tham số > Cơ bản:
- Bạn có thể thay đổi số lượng epoch, nhưng tôi sẽ giữ 6 để bắt đầu.
Tìm kiếm trên internet về ý nghĩa của từng trường, việc giải thích tất cả nằm ngoài phạm vi cho đến bây giờ, nhưng bạn có thể đọc ở đây: Các tham số đào tạo LoRA
Sử dụng phần cứng
Hầu hết các cấu hình thay đổi yêu cầu phần cứng.
Đây là những cái đã hoạt động với tôi, sử dụng RTX2060 super với 12GB Vram — Đối với FLUX, tôi đã nâng cấp lên RTX 4060 TI 16GB Vram.
Ví dụ, RTX2060 của tôi không hỗ trợ bf16 như 3060s, vì vậy tôi sử dụng fp16. Điều này sẽ tiết kiệm bộ nhớ cho tôi, nhưng nó như vậy và với 12G đã hoạt động.
Sau khi thay đổi tất cả những điều đó, nhấp vào “Bắt đầu đào tạo”. Bạn sẽ thấy điều này trong bảng điều khiển:
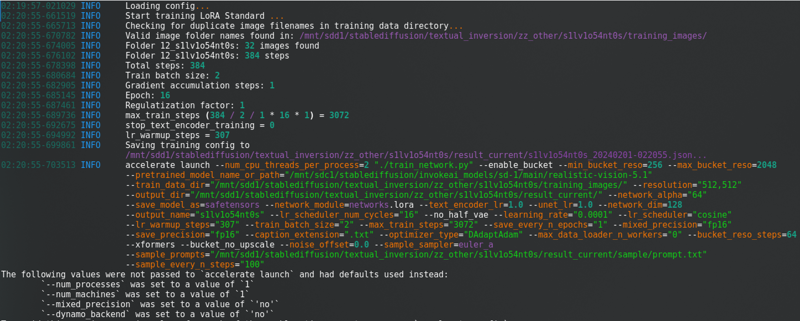
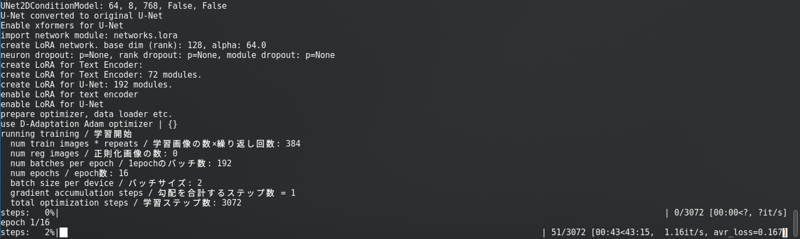
Với một thanh tiến trình dài.
SD1.5: Tôi không lưu trữ latents vào đĩa. Nó nhanh hơn, nhưng sử dụng gần như cùng một Vram như SDXL.
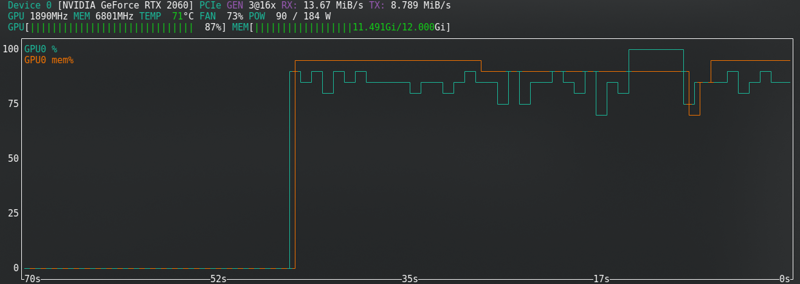

SDXL:
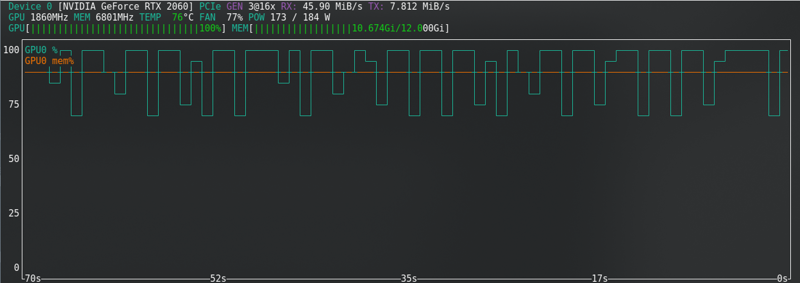

FLUX: Gần giới hạn ngay cả với thẻ mới!!!!!
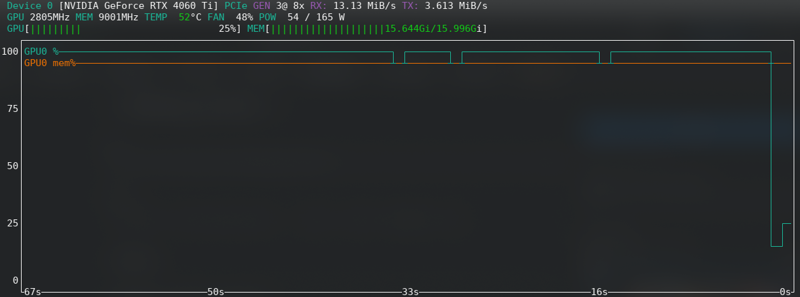
Lỗi hết bộ nhớ
Nếu bạn nhận được lỗi CUDA hết bộ nhớ, thì bạn đang ở giới hạn. Bật lưu trữ latents vào đĩa, chuyển từ fp16 sang bf16 nếu phần cứng của bạn hỗ trợ, giảm kích thước lô từ 2 xuống 1.
Đối với Flux, bạn có thể bật “Chế độ chia”. Điều này giảm rất nhiều VRAM, nhưng gần như gấp đôi thời gian đào tạo.
Các tùy chọn khác là: Đóng tất cả các chương trình, ngắt kết nối màn hình thứ 2 của bạn, giảm độ phân giải hiển thị, nếu trên Linux hãy tạm thời chuyển sang môi trường desktop nhẹ hơn, khi kích hoạt quá trình đào tạo hãy đóng trình duyệt và chỉ kiểm tra trạng thái với dòng lệnh mở.
Nếu bạn không thể giải quyết, hãy tìm kiếm trên internet. Nếu vẫn gặp lỗi, thì từ bỏ và đào tạo trên CivitAI.
Xem trước quá trình đào tạo
Mỗi 100 bước (bạn có thể thay đổi điều này) quá trình đào tạo sẽ tạo ra một hình ảnh mẫu trong thư mục results_current/sample, sau đó bạn có thể có ý tưởng nếu nó đang hoạt động hay không.
Các kết quả sẽ cải thiện theo thời gian khi nó đang học.

Kết quả đào tạo
Khi nó hoàn thành, thư mục sẽ trông như thế này:
Bạn có thể kiểm tra qua các hình ảnh mẫu nếu nó bị overtrained hoặc undertrained. Bạn sẽ thấy điều đó khi chạy LoRA cũng vậy.
Overtrained
Nếu mô hình bị overtrained, các hình ảnh sẽ “bị pixel hóa như đất sét”... Tôi không biết mô tả như thế nào. Các hình ảnh xem trước sẽ bắt đầu bị biến dạng.
Xem bằng mắt, một hình ảnh được tạo ra:

Đôi khi nó không đạt được kết quả tồi tệ như vậy, nhưng khuôn mặt NGỪNG trông giống như người đã được đào tạo cho đến khi nó bị biến dạng trong các epoch sau.

Giải pháp rất đơn giản: Chỉ cần thử các epoch trước và xem epoch gần nhất mà hoạt động tốt. Dựa trên hình ảnh mẫu, bạn có thể dễ dàng tìm ra cái tốt và tìm tệp LoRA được tạo ra vào khoảng thời gian đó.
RẤT KHÓ ĐỂ CHỌN MỘT CÁI!!! Nhưng phải làm. Thử càng nhiều càng tốt.
Undertrained
Nếu nó bị undertrained (Khuôn mặt chân dung không giống như người và có vẻ như là một sự kết hợp của người chung chung từ mô hình SD, hoặc đối tượng không có các chi tiết mong muốn) bạn có thể tiếp tục đào tạo.

Trong hình ảnh ví dụ này, bạn thấy rằng các chi tiết đang thiếu, như chiếc microphone hòa vào cà vạt.
Sự khác biệt giữa overtraining là thiếu chi tiết.
Nếu bạn đã đóng Kohya, không sao, chỉ cần tải json mà nó tạo ra trong thư mục kết quả và tất cả các cấu hình đã sử dụng sẽ được tải lên.
Trong Tham số > Cơ bản, bạn có trường Cân nặng mạng LoRA nơi bạn có thể thêm bất kỳ lora nào bạn muốn tiếp tục đào tạo.
Đổi tên cái cuối cùng bạn có thành bất kỳ tên nào khác, sao chép vị trí của nó vào trường này, thay đổi số lượng epoch thành 2 hoặc 3 (tùy thuộc vào bạn cần bao nhiêu để tiếp tục đào tạo) và nhấp vào bắt đầu đào tạo một lần nữa. Nó sẽ tiếp tục quá trình đào tạo.
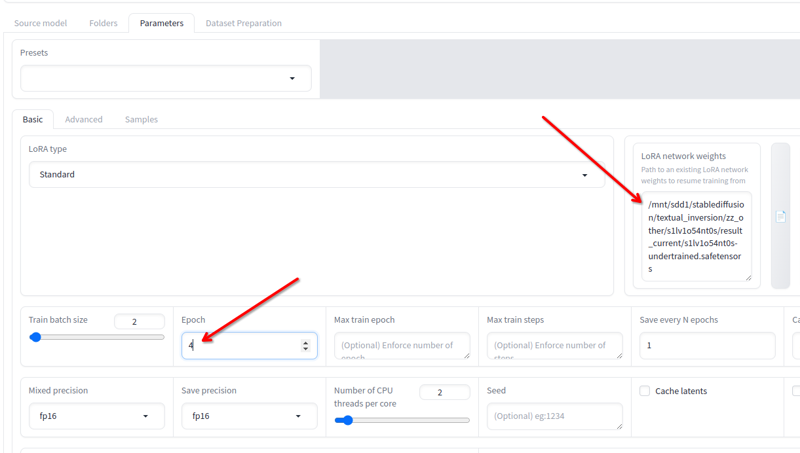
Bạn có thể làm điều đó cho đến khi nó tốt!
Hoàn thành!
Đổi tên epoch lora cuối cùng bạn muốn (hoặc giữ nếu kết quả cuối cùng là tốt) và sử dụng nó.
Đây là ví dụ SD1.5:

Đây là ví dụ Flux:






