
คู่มือตัวสร้าง AI Hentai ของ BetterWaifu: พื้นฐานการเขียนพรอมต์
g
By gerogero
Updated: March 13, 2026
เครื่องสร้าง AI นั้นง่ายมาก: คุณเพียงแค่พิมพ์คำสั่งและคลิก “สร้าง” เพื่อให้ได้ภาพของคุณ
คำถามที่ผู้คนมีเมื่อเริ่มต้นคือ ไม่ใช่ ‘ฉันจะสร้างได้อย่างไร’ แต่เป็น ‘ฉันจะสร้างภาพที่ดีกว่าได้อย่างไร’
คู่มือนี้มีเป้าหมายเพื่อตอบคำถามนั้น มันเป็นผลจากการทดลองอย่างต่อเนื่องและการเรียนรู้จากเว็บไซต์ BetterWaifu ซึ่งมีการสร้างภาพหลายแสนภาพทุกวัน
ทุกอย่างเริ่มต้นที่ Danbooru
สำหรับใครก็ตามที่พยายามปรับปรุงคำสั่งของพวกเขา ข้อเสนอแนะแรกใน เซิร์ฟเวอร์ Discord ของเรามักจะเป็นการเรียกดู Danbooru
แต่สำหรับผู้ใช้ครั้งแรก Danbooru นั้นสับสนมาก มันดูเหมือนการรวมกันที่ยุ่งเหยิงของภาพและแท็ก ดังนั้นมันช่วยเราในการสร้าง waifus ที่ดีกว่าได้อย่างไร?
Danbooru เป็นบอร์ดภาพอนิเมะที่ใหญ่ที่สุดในโลก โดยไม่มีข้อยกเว้น ทุก เครื่องสร้าง AI อนิเมะใช้ภาพของมันในการฝึกอบรม มีเว็บไซต์ ‘booru’ หลายแห่งที่ใช้เลย์เอาต์เดียวกัน เช่น Rule34 และ Gelbooru แต่ Danbooru เป็นที่ใหญ่ที่สุด
ใน Danbooru อาสาสมัครจะทำการแท็กภาพทั้งหมดอย่างละเอียดตามเนื้อหา แท็กเหล่านี้มีตั้งแต่ลักษณะทางกายภาพ “large_breasts”, “red_hair” ไปจนถึงวัตถุ “book” และการกระทำ “fellatio”
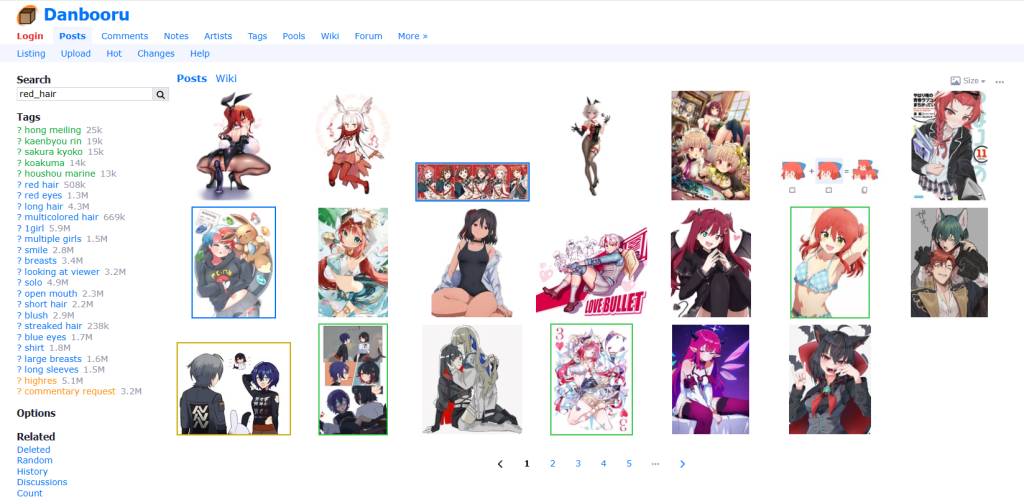
คุณสามารถใช้แท็กเหล่านี้โดยตรงในคำสั่งของคุณ (ไม่มีความแตกต่างระหว่างขีดล่างและช่องว่างในคำสั่ง)
แนวคิดหลัก: หากแท็กมีภาพจำนวนมาก หมายความว่ามีเนื้อหามากมายในการฝึก AI บนแท็กนั้น ดังนั้น BetterWaifu และเครื่องสร้าง AI อื่นๆ สามารถสร้างมันได้โดยทั่วไป
ดังนั้นการสร้างคำสั่งที่มีประสิทธิภาพจึงเป็นกระบวนการที่เริ่มต้นจากการค้นหาแท็กที่ดีและใช้มันโดยตรงในคำสั่งของคุณ
พื้นฐานของการแท็ก
- แท็กที่มีภาพมากขึ้นจะมีความแข็งแกร่งมากขึ้น AI สามารถสร้างได้เฉพาะสิ่งที่มันรู้ และสิ่งที่มันรู้จะถูกกำหนดโดยภาพที่มันได้รับการฝึกอบรม นั่นหมายความว่าจำนวนแท็กที่ภาพมีอยู่ใน Danbooru มักจะเป็นการประมาณการที่ดีว่ามันสามารถสร้างได้หรือไม่ กฎทั่วไปที่ค่อนข้างหยาบ: แท็กควรมีภาพอย่างน้อย 1k เพื่อให้ AI รับรู้ได้ หากมีอย่างน้อย 3k จะมีโอกาสสูงมากที่ AI จะสามารถสร้างได้อย่างถูกต้อง
- สิ่งนี้ใช้ได้กับแท็กตัวละครด้วย สิ่งสำคัญคือต้องใช้วิธีการเขียนชื่อของ Danbooru ดังนั้น “yor briar” สามารถสร้างตัวละครที่ถูกต้องได้ แต่ “yor forger” ไม่สามารถ อย่างไรก็ตาม กฎ “แท็กมากยิ่งดี” มีข้อควรระวังสำหรับตัวละคร หากแฟรนไชส์ไม่เป็นที่นิยมมากนัก โอกาสที่เครื่องสร้างจะสามารถสร้างตัวละครในนั้นได้ก็มีน้อย นอกจากนี้ ผู้สร้างโมเดล AI อาจเลือกที่จะไม่รวมแฟรนไชส์/ตัวละครด้วยเหตุผลหลายประการ
- เป็นมินิมอลลิสต์ที่แม่นยำ หลายคนชอบใช้คำฟิลเลอร์มากมายในคำสั่งของพวกเขา นี่เป็นเทคนิคจากวันเก่าๆ ของ AI-gen ประมาณปี 2022 เราไม่จำเป็นต้องทำเช่นนี้อีกต่อไป แท็กมากเกินไปทำให้เกิดเสียงรบกวนและนำไปสู่ผลลัพธ์ที่มีคุณภาพต่ำกว่า รักษาสิ่งต่างๆ ไว้ในระดับขั้นต่ำสุด ใส่เฉพาะสิ่งที่คุณต้องการเห็นจริงๆ เช่น อย่าใส่ ‘nsfw’ ในคำสั่งเมื่อมันชัดเจนว่าเป็นฉากที่ชัดเจนแล้ว
- สร้างคำสั่งจากสิ่งที่คุณเห็น ไม่ใช่สิ่งที่คุณรู้ อย่าใช้แท็กของสิ่งที่ไม่สามารถมองเห็นได้ในภาพสุดท้ายในคำสั่งของคุณ ตัวอย่างเช่น ตัวละครมักถูกเรียกว่า ‘นักล่ามอนสเตอร์’ แต่สิ่งนี้ไม่มีอะไรเกี่ยวข้องกับภาพที่คุณต้องการสร้าง ดังนั้นให้ตัดสิ่งนี้ออก
โอเค ฉันเชื่อแล้ว แต่ฉันจะหาทางหาทางแท็กที่ดีได้ที่ไหน?
เริ่มจาก รายการกลุ่มแท็ก ขนาดใหญ่ ที่นี่ฉันจะนำเสนอบางกลุ่มที่น่าสนใจเป็นพิเศษ
แท็กหน้าอก
แท็กที่ดีที่สุดในการระบุขนาดหน้าอก ความชัดเจน เสื้อผ้าสำหรับการเน้นหน้าอก
การกระทำทางเพศ
รายการยาวของการกระทำทางเพศที่หลากหลาย
ท่าทางทางเพศ
ท่าทางทางเพศรวมถึงท่าทางการมัด
การเปลือย
ประเภทของการเปลือย การเปลือยบางส่วน ชุดว่ายน้ำ
พื้นหลัง
สีพื้นหลัง
แสง
ประเภทของแสงสามารถส่งผลกระทบต่อผลลัพธ์ของคุณได้อย่างมาก
การจัดองค์ประกอบภาพ
มุม มุมมอง การจัดองค์ประกอบ
ใบหน้า
อารมณ์ทางใบหน้า อารมณ์ (รวมถึงอารมณ์ทางเพศ) ลักษณะใบหน้า
การรวมแท็กเข้าด้วยกัน: มาสร้างคำสั่งกันเถอะ!
ไม่รู้จะเริ่มจากไหน? ไปดูที่ กลุ่มแท็ก และคิดเกี่ยวกับสิ่งที่สำคัญที่สุดในภาพในฝันของคุณ
ฉันมักจะชอบที่จะใช้รูปแบบโดยใช้ 5 กลุ่มคำ โดยมีหมวดหมู่ย่อยอยู่ภายใน
ฉันพยายามแยกแนวคิดเหล่านั้นด้วยการขึ้นบรรทัดใหม่ ซึ่งช่วยให้ฉันปรับเปลี่ยนได้อย่างรวดเร็ว บรรทัดใหม่ไม่ส่งผลกระทบต่อการสร้าง
โปรดจำไว้ว่านี่เป็นแนวทางที่ค่อนข้างหยาบ มันโอเคที่จะผสมผสานลำดับนี้ โดยเฉพาะภายในหมวดหมู่
1. การจัดองค์ประกอบ
- สไตล์ (ภาพถ่ายที่สมจริง พาเลตสี ฯลฯ)
- มุมมอง
- แสง เวลาในวัน (กลางวัน กลางคืน พระอาทิตย์ตก ฯลฯ)
2. วัตถุ
- วัตถุหลัก (1boy, 1girl, วัตถุ, ทิวทัศน์ ฯลฯ)
(1girl เป็นเพียงวิธีของ Danbooru ในการบอกว่า ‘1 สาว’ และแยกออกจาก 2girls และ 3girls และอื่นๆ)
3. การกระทำ
4. ร่างกาย
- ท่าทาง
- ลักษณะหลัก (ขนาด น้ำหนัก ประเภทของร่างกาย ไขมันในร่างกาย สีผิว ฯลฯ)
- องค์ประกอบของร่างกาย (ขนาดหน้าอก, หัวนม, ก้น ฯลฯ)
- เกี่ยวกับใบหน้า (สีตา ทรงผม ฯลฯ)
- อารมณ์ (มีความสุข ประหลาดใจ จริงจัง มุ่งมั่น ฯลฯ)
- เสื้อผ้า
5. พื้นหลัง
- สภาพแวดล้อมหลัก (ในร่ม กลางแจ้ง ฯลฯ)
- สภาพอากาศ (ลม ฝน หิมะ ฯลฯ)
- วัตถุ (เฟอร์นิเจอร์ ยานพาหนะ ฯลฯ)
รอเดี๋ยว มันไม่ยาวและซับซ้อนเกินไปเหรอ?
ใช่! แต่คุณไม่จำเป็นต้องมีหมวดหมู่ที่คุณไม่ต้องการ และคำเดียวก็สามารถเพียงพอสำหรับหมวดหมู่ได้ มันเกี่ยวกับระดับการควบคุมที่คุณต้องการ มาดูตัวอย่างกัน
ฉันคิดถึงชุดแม่บ้านสีดำถ่ายจากด้านล่าง พื้นหลังไม่สำคัญ แต่ฉันต้องการเอฟเฟกต์ภาพยนตร์ที่เจ๋ง สำหรับแรงบันดาลใจ ฉันจะคลิกที่ลิงก์ด้านบนในแต่ละหมวดหมู่และหมวดหมู่ย่อยที่ฉันสนใจ
การจัดองค์ประกอบ: from_below, วัตถุ:
เกี่ยวกับความยาวของคำสั่ง
คำสั่งจะแบ่งตามคำ (หรือกลุ่มคำ) เพื่อเปลี่ยนเป็นการแทนค่าทางตัวเลขที่เรียกว่าโทเค็น ขึ้นอยู่กับว่าใช้โมเดลใดและโทเค็นถูกทำให้เป็นมาตรฐานอย่างไร บางส่วนของคำสั่งของคุณจะมีความสนใจมากหรือน้อยกว่า กฎของฉัน: ยิ่งคำสั่งยาวเท่าไหร่ คุณก็จะมีการควบคุมมากขึ้นต่อคำสั่งทั้งหมด
นี่คือแหล่งข้อมูลบางส่วนหากคุณต้องการอ่านเพิ่มเติมเกี่ยวกับเรื่องนี้:
โทเค็นกับโมเดล SDXL และ SD15 – Alen Knight
การทำให้เป็นมาตรฐานของโทเค็น & การตีความน้ำหนัก – BlenderNeko (Github)
ตัวอย่าง
นี่คือตัวอย่างตามโครงสร้าง ฉันมักจะใส่บรรทัดพักเพื่อให้มองเห็นพื้นที่หลักของคำสั่งได้ดีขึ้น
sidelighting, light particles,
1girl, ginger, solo, smirk
sweat, freckles, small breasts,
ginger hair, long hair, straight hair,
blue eyes, glowing eyes, glasses, looking at viewer,
smile, smirk, grin, frown,
white tank top,
indoor, library,
sunset, sunny, daylight,
desk, chair, ดังที่คุณเห็น บรรทัดพักไม่ได้แบ่งออกเป็น 5 ฟิลด์ของโครงสร้างอย่างสมบูรณ์ ขึ้นอยู่กับสิ่งที่คุณต้องการสร้าง มันอาจทำให้มีความหมายมากขึ้นในการแยกส่วนที่เล็กและยาวออกจากกัน ที่นี่ วัตถุ, การกระทำ และ ท่าทาง ของร่างกายถูกจัดกลุ่มร่วมกัน: การแยกพวกมันจะทำให้เกิดความยุ่งเหยิงทางสายตามากกว่าสิ่งอื่นใด
ดังที่คุณเห็น บรรทัดพักไม่ได้แบ่งออกเป็น 5 ฟิลด์ของโครงสร้างอย่างสมบูรณ์ ขึ้นอยู่กับสิ่งที่คุณต้องการสร้าง มันอาจทำให้มีความหมายมากขึ้นในการแยกส่วนที่เล็กและยาวออกจากกัน ที่นี่ วัตถุ, การกระทำ และ ท่าทาง ของร่างกายถูกจัดกลุ่มร่วมกัน: การแยกพวกมันจะทำให้เกิดความยุ่งเหยิงทางสายตามากกว่าสิ่งอื่นใด
กรณีการใช้งาน
นี่คือกรณีการใช้งานและคำหลักที่ชื่นชอบ ฉันพยายามจัดระเบียบตามกลุ่มที่มีเหตุผล จากทั่วไปไปจนถึงเฉพาะเจาะจงมากขึ้น ฉันแนะนำให้เลือกเฉพาะสิ่งที่เหมาะสมกับคุณแทนที่จะคัดลอกและวางทั้งบรรทัด
คุณจะพบการอ้างอิงถึงตำแหน่งที่ฉันวางไว้ในโครงสร้าง ฉันจะใช้ ID ด้วยรูปแบบ [xx.yy] โดยใช้ตัวย่อของหมวดหมู่และหมวดหมู่ย่อย
โปรดจำไว้ว่าบางส่วนอาจไปสูงหรือต่ำกว่าในลำดับการปรากฏ (เช่น กลับหัว อาจถูกวางเป็น [compos.pov] หรือ [body.posture])
ทั่วไป
นี่คือสิ่งที่ฉันใช้ในเกือบทุกคำสั่งเพื่อมีอิทธิพลต่อคุณภาพโดยรวมของภาพ ฉันมักจะเพิ่มคำหลักเชิงลบเพิ่มเติมหากมีสิ่งที่ฉันไม่ชอบปรากฏขึ้น แต่ไม่ก่อนหน้านั้น อีกครั้ง ฉันชอบที่จะรักษาสิ่งต่างๆ ให้ง่ายและสั้น
รายการต่อไปนี้ครอบคลุมกรณีคลาสสิกบางประการ โดยละเอียดทั้ง เชิงบวก และ เชิงลบ ของคำสั่ง
- คุณภาพ (SD1.5)
(absurdres, คุณภาพดีที่สุด, มาสเตอร์พีซ:1.4),
(คุณภาพต่ำสุด, คุณภาพต่ำ, lowres, คุณภาพปกติ:1.4) - คุณภาพ (Pony)
score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up,
score_6, score_5, score_4, - รายละเอียด
รายละเอียด, ร่างกายที่มีรายละเอียด, ใบหน้าที่มีรายละเอียด - เชิงลบ+
ข้อความ, โลโก้, ลายน้ำ, ตัวเลข, มุมมองหลายมุม, ขาวดำ,
สัดส่วนไม่ดี, ความไม่สมเหตุสมผลทางกายวิภาค, มือไม่ดี, ใบหน้าที่ไม่ดี
หมายเหตุ: เชิงลบ+ เป็นรายการเพิ่มเติมที่ฉันเลือกตามสถานการณ์ ในประสบการณ์ของฉัน คำหลักเชิงลบที่เกี่ยวข้องกับทางกายวิภาคไม่ได้ปรับปรุงผลลัพธ์เสมอไป ดังนั้นฉันจึงเก็บไว้ข้างๆ ในกรณีที่ฉันต้องการมัน
ฉาก
- การกระทำ [compos.style]: เส้นการเคลื่อนไหว, เส้นเน้น, เส้นความเร็ว, ภาพหลัง, เบลอการเคลื่อนไหว, กระเด้ง(+ผม, หน้าอก, ก้น, ฯลฯ), คลื่นก้น, หยดเหงื่อ, สั่น, สั่น, กระตุก, เสียงเอฟเฟกต์, เหงื่อระยิบระยับ
- แสง [compos.light]: แสงจากด้านหลัง, แสงสลัว, แสงริม, พลบค่ำ, พระอาทิตย์ตก, รุ่งอรุณ, พระอาทิตย์ขึ้น, อนุภาคแสง, รังสีแสง, แสงแดด, แสงแดดที่กระจาย, เงาต้นไม้, รอยแยกของแสง
- ร้อน [body.posture]: เหงื่อ, เหงื่อออก, เหงื่อออกมาก, เหงื่อออกอย่างหนัก, หยดเหงื่อ, เปียก (+เสื้อผ้า,ผม, ฯลฯ), เสื้อผ้าที่เปียก, ร้อน, โรคลมแดด, แก้มแดง, แก้มแดงทั้งหน้า, แก้มแดงที่ร่างกาย, หายใจ, หายใจหนัก, ร่างกายที่มีไอน้ำ,
- แก๊งค์แบงค์ [subject]: หลายชาย/หญิง, เซ็กส์กลุ่ม, แก๊งค์แบงค์, ออจี, สุมหัว, รถไฟแห่งความรัก, สามคน,
หมายเหตุ: จำนวนที่แน่นอนด้วย xชาย/xหญิง.
วัตถุ
- ผมหลากสี [subject],[hair]: ผมหลากสี, ผมเกรเดียนต์, ปลายสี, <color-1> ผม, <color-2> ผม
- ใบหน้าที่มีรอยยิ้ม [body.express]: รอยยิ้ม, มีความภาคภูมิใจ, หน้าบึ้ง, ดอยากาโอ,
- ยากูซ่า [subject],[body]: ยากูซ่า, รอยสัก (อิเรซูมิ, รอยสักทั้งตัว, ฯลฯ), การเจาะ (จมูก, สะดือ, หัวนม, ฯลฯ), การแต่งหน้า
- ปีศาจ [subject],[body]: ปีศาจ, ปีศาจสาว, เขา (ปีศาจ, มังกร, ม้วน, วัว, ฯลฯ), หาง (ปีศาจ, ยกขึ้น, ฯลฯ), ผิวสี (แดง, ดำ, ฯลฯ)
- กอบลิน [subject],[body]: กอบลิน, กอบลินหญิง, ผิวเขียว, หูแหลม, เขี้ยว
- ฟูรี [subject]: ฟูรี, ฟูรีหญิง, ฟูรีที่มี [ฟูรี/ไม่ฟูรี], <color> ขน, เขี้ยว(s)





