
NSFW-LoRA trainieren (aktualisiert mit FLUX)
g
By gerogero
Updated: March 13, 2026
Modelle die für das Training verwendet werden
Für SD 1.5 realistische Fotos:
- Training: Realistic Vision 5.1
Dieses Modell wurde bei den Mai-Merges hinzugefügt und ist auch Teil eines Merges. Funktioniert gut mit fast allen anderen realistischen Modellen. Der v6 funktioniert aus irgendeinem Grund nicht so gut. - Generation: Realistic Vision 5.1 und ein img2img mit einem Denoise von 0.1 unter Verwendung von PicX Real 1.0. RV allein erledigt die Arbeit, aber ich mochte diese Kombination.
Für SD 1.5 Anime:
- Training: AnyLora
Dieses Modell ist ein Klassiker für das Training. - Generation: Azure Anime v5
Für SDXL insgesamt (einschließlich Pony und Illustrious hier):
- Training: SDXL Basis-Modell
- Generation: Dreamshaper XL Turbo. Ich benutze 7 Schritte und mache dann ein img2img mit dem gleichen Prompt, aber einem neuen Seed, dann ist das Ergebnis schön!
Für FLUX insgesamt:
- Modell: flux1-Dev-Fp8.safetensors (11,1 GB Datei)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 Encoder: t5xxl_fp8_e4m3fn.safetensors
- 16GB Vram benötigt. Aber du kannst diesen anderen Artikel hier ausprobieren.
Tools die ich benutze
- Für das Training musst du installieren: Kohya_ss
Aber manchmal führe ich einfach ein Skript aus, das ich erstellt habe, um den Prozess zu beschleunigen. Es ruft die Kohya-Skripte mit allen Parametern auf. Ich werde am Ende darüber sprechen.
Der sd3-flux.1Branch wird für Flux benötigt. - Generation: InvokeAI
Entschuldigung Leute, ich habe hier Automatic1111 und ComfyUI, aber ich liebe InvokeAI. - Lora Metadata Viewer: https://civitai.com/models/249721
Datensatzvorbereitung
Dies ist der wichtigste Teil. Du musst Bilder von der Person, dem Objekt oder was auch immer du trainieren möchtest, sammeln.
Es gibt einige Dinge zu beachten
- Vermeide niedrige Auflösungen oder pixelige Bilder. Ich empfehle kein Upscaling.
- Vermeide Bilder, die zu unterschiedlich sind. Ich halte mich normalerweise an Porträts.
- Vermeide Bilder mit zu viel Make-up, vielen Ohrringen und Halsketten, seltsamen Posen.
- HÄNDE. Vermeide Bilder, in denen Hände zu oft in seltsamen Positionen erscheinen.
- Ich schneide die Bilder einzeln, um sicherzustellen, dass sie nur das Motiv zum Trainieren enthalten, Logos, andere Personen, verschwendete Räume usw. zu entfernen.
Hier ist der Datensatz, den ich für Silvio Santos lora erhalten habe:

Du kannst sehen, dass es sich um Porträts handelt. Unterschiedliche Hintergründe und Kleidungsfarben sind ein MUSS. Gesichter, die in verschiedene Richtungen schauen, ebenfalls.
Hinweis zur Symmetrie
Überprüfe, ob die rechten und linken Seiten der Person in allen Bildern konsistent sind. Dies ist möglicherweise nicht der Fall bei Selfies, die normalerweise invertiert sind.
Das menschliche Gesicht ist nicht symmetrisch, daher kann es, wenn du eine gemischte Seitenorientierung während deines Trainings hast, so aussehen:

Bitte überprüfe die Orientierung deines gesamten Datensatzes!!
Wenn die Vorschau-Bilder nach einer Weile alle gleich aussehen, könnte dies der Grund sein, da SD versuchen wird, beide Seiten zu lernen, und der Unterschied in der Symmetrie könnte dazu führen, dass der Verlust bei einigen invertierten Bildern etwas höher ist, sodass das Lernen bei einigen wenigen Bildern stecken bleibt.
Anzahl der Bilder
- 5 bis 10: Dein Lora wird nicht viele Variationen haben, kann aber funktionieren.
- 11 bis 20: Gute Anzahl. Kann ein gutes Lora generieren.
- 21 bis 50: Dieser große Bereich ist das, was wir wollen!
- 50 bis 100: Zu viel, funktioniert aber, wenn du Porträts UND Ganzkörperbilder mischen möchtest.
- > 100: Verschwendung von Arbeit.
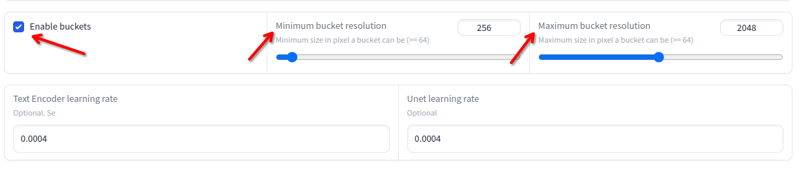
Auflösung
Die Auflösung kann von 256x bis 2048x variieren. Vermeide Bilder unter oder über diesen Werten. Du musst nicht skalieren, wenn sie innerhalb dieser Werte liegen, da das Training dies automatisch in Buckets erledigt:
Die Ordnerstruktur:
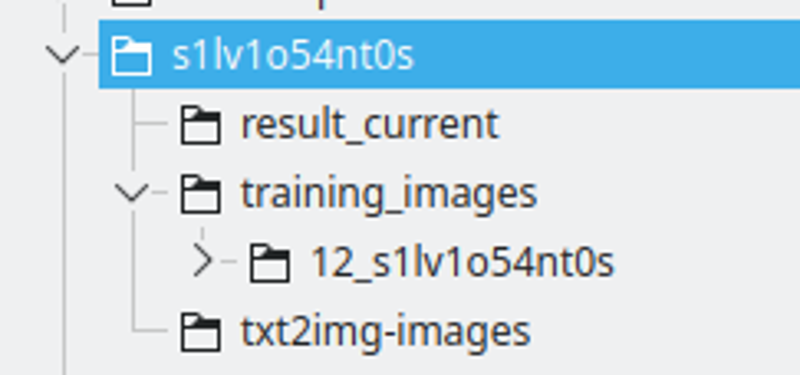
Ich erstelle einen Ordner mit dem Namen der LoRA-Zeichenfolge. Ich benenne die Zeichenfolge, indem ich einige Buchstaben durch Zahlen ersetze, um sicherzustellen, dass es sich um ein einzigartiges Token über viele Modelle handelt.
Der result_current wird der Ort sein, an dem Kohya die Ergebnisse speichert.
Die Trainingsbilder werden das Verzeichnis enthalten, das die Trainingsbilder enthält. Die Namenskonvention ist: 400 / Anzahl der Bilder, ein Unterstrich und die Lora-Zeichenfolge. Dies wird die Anzahl der Wiederholungen sein, die Kohya durchführen wird. Ich finde diese Zahl einen guten Punkt, um ein gutes Intervall zwischen den Epochen zu haben.
txt2img-images ist der Ort, an dem ich generierte Bilder mit der LoRA speichere – Optional.
Bildunterschriften
Dies ist der Prozess, bei dem du beschreibst, was jedes Bild ist, damit SD weiß, wie es das vorhandene Modell verwenden kann, um die Trainingsbilder aus dem Rauschen zu erstellen.
In Kohya, im Tab „Utilities“, haben wir Blip-Bildunterschriften. Ich benutze dies mit diesen Konfigurationen:
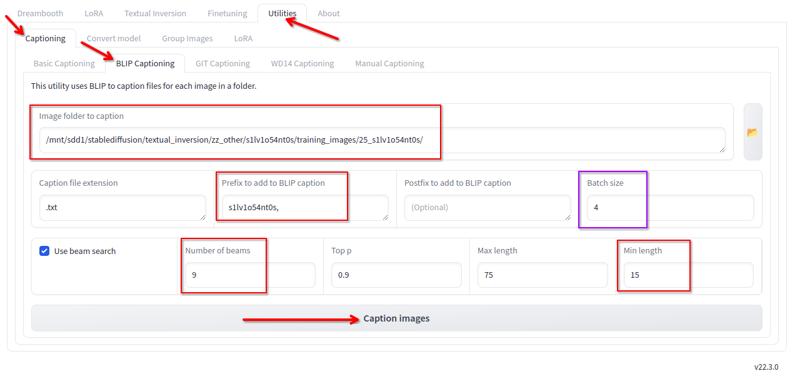
Ich ändere Folgendes:
- Ordner, in dem sich die Bilder befinden.
- Präfix ist der Lora-Name und ein Komma.
- Anzahl der Strahlen 9.
- Minimale Länge 15.
- Batch-Größe 4.
- Alle anderen Werte lasse ich auf den Standardwerten.
Klicke auf „Bildunterschrift“, und es wird nach einer Weile die Bildunterschriften generieren:
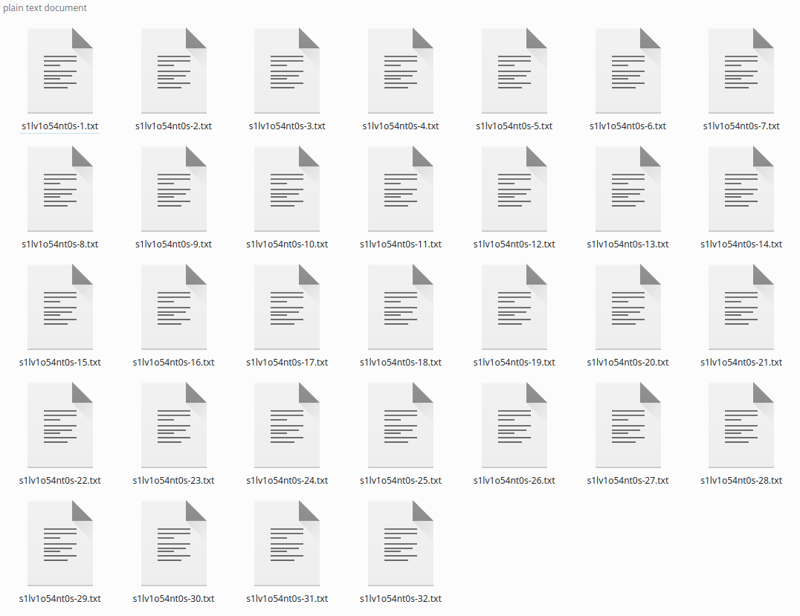
Wenn du nur wenige Bilder hast, kannst du die Bildunterschriften korrigieren, da Blip es LIEBT, Phrasen wie „eine Fernbedienung haltend“ oder „Mit einem Mikrofon in der Hand“ hinzuzufügen, die nicht zutreffen. Ich ignoriere das einfach, und es hat auf diese Weise funktioniert, da die allgemeine Bildunterschrift gut ist.
*Du könntest sagen, dass diese „grundlegende“ Bildunterschrift nicht gut für Flux ist, dass eine bessere Bildunterschrift mit LLM besser ist, aber es hat für mich gut funktioniert.
Regularisierungsordner
In der Vergangenheit, für die ersten Loras, die ich veröffentlicht habe, verwendete ich einen Regularisierungsordner mit mehr als 4K Frauenbildern. Ich habe aufgehört, ihn zu verwenden , da er nur erforderlich ist, wenn dein Datensatz nicht beschriftet und vielfältiger ist.
Seine Verwendung verdoppelt die benötigte Zeit und die Schritte.
Verwende ihn nicht.
Das Training durchführen
Hier werden wir das Training durchführen. Für SD1.5 erfordern diese Konfigurationen 8GB Vram, SDXL erfordert 10GB Vram, Flux erfordert 16GB Vram.
Die Installation von Kohya fällt nicht in den Rahmen dieses Leitfadens.
Kohya-Konfigurationen
SD1.5 Konfigurationen: https://jsonformatter.org/a3213d
SDXL Konfigurationen: https://jsonformatter.org/66e5c8
FLUX Konfigurationen: https://jsonformatter.org/45c1fc
* Lass mich wissen, wenn die Links ablaufen
* Für FLUX beschränke ich das Training auf 1800 Schritte (bereits in der obigen Konfigurationsdatei), aber nach etwa 1200 Schritten ist das LoRA bereits gut.
* Auch für FLUX waren meine oben genannten Einstellungen nicht konvergierend für ANIMES und CARTOONS. Daher musst du möglicherweise die –learning_rate=0.0004 –unet_lr=0.0004 auf 0.001 oder 0.002 erhöhen. Damit wird das Training in weniger Schritten gut, könnte aber leichter überanpassen.
Lade einfach diese Dateien im Kohya LORA-Tab — NICHT IM DREAMBOOT-TAB — klicke auf die Konfigurationsdatei und lade sie.
Konfigurationen, die du ÄNDERN MUSST:
Modell- und Ordnerabschnitt:
- Bildordner – der Trainingsbilder-Ordner, den wir zuvor erstellt haben. NICHT der Ordner mit der Nummer, der übergeordnete Ordner.
- Ausgabeverzeichnis – der result_current-Ordner, den wir zuvor erstellt haben.
- Ausgabebezeichner – der Zeichenfolgenname der Lora.
Parameter-Tab > Erweitert > Proben:
- Ändere den Prompt. Er muss einfach sein, er wird verwendet, um die Beispielbilder zu generieren. Halte es einfach.
Parameter-Tab > Grundlegend:
- Du kannst die Anzahl der Epochen ändern, aber ich würde mit 6 beginnen.
Suche im Internet nach der Bedeutung jedes Feldes, es fällt jetzt nicht in den Rahmen, sie alle zu erklären, aber du kannst hier lesen: LoRA-Trainingsparameter
Hardware-Nutzung
Die meisten Konfigurationen ändern die Hardware-Anforderungen.
Dies sind die, die für mich funktioniert haben, mit einer RTX2060 Super mit 12GB Vram — Für FLUX habe ich auf eine RTX 4060 TI mit 16GB Vram aufgerüstet.
Zum Beispiel unterstützt meine RTX2060 kein bf16 wie die 3060s, daher verwende ich fp16. Das würde mir Speicher sparen, aber es ist, wie es ist, und mit 12G hat es funktioniert.
Nachdem du all das geändert hast, klicke auf „Training starten“. Du wirst dies in der Konsole sehen:
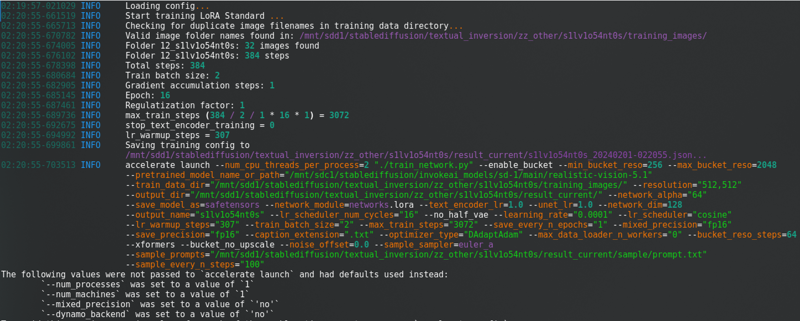
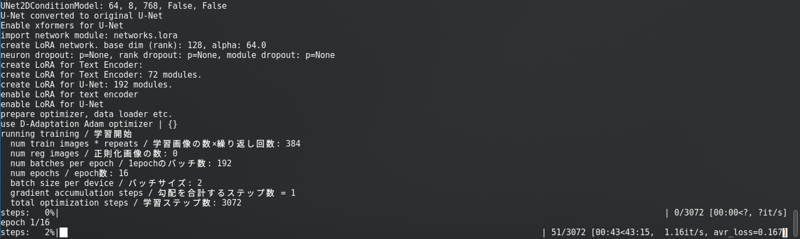
Mit einem langen Fortschrittsbalken.
SD1.5: Ich speichere keine latenten Daten auf der Festplatte. Es ist schneller, verbraucht aber fast den gleichen Vram wie SDXL.
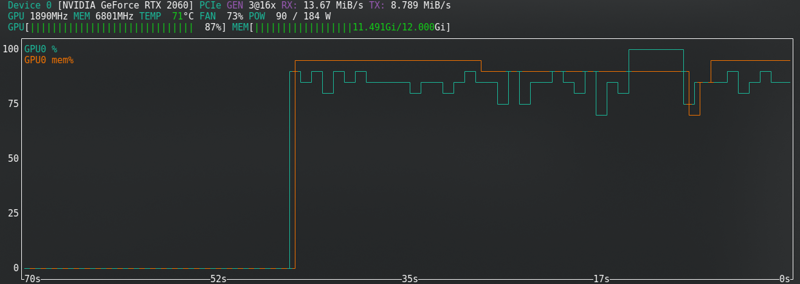

SDXL:
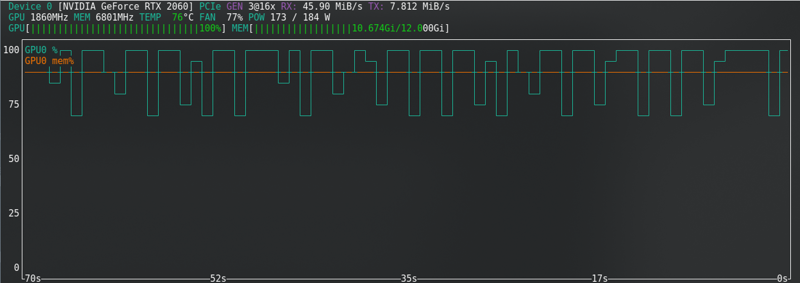

FLUX: Nahe der Grenze, selbst mit der neuen Karte!!!!!
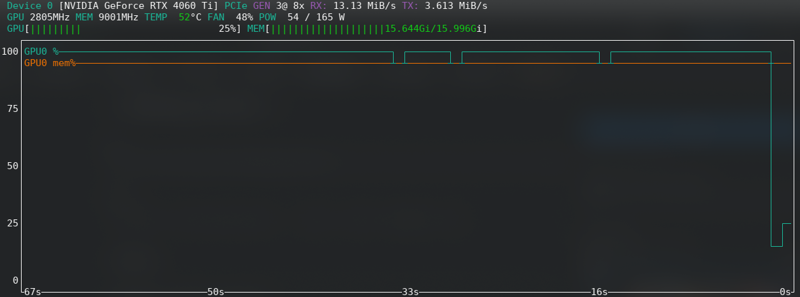
Speicherfehler
Wenn du CUDA-Speicherfehler erhältst, dann bist du am Limit. Aktiviere das Speichern latenter Daten auf der Festplatte, wechsle von fp16 zu bf16, wenn deine Hardware dies unterstützt, reduziere die Batch-Größe von 2 auf 1.
Für Flux kannst du den „Split-Modus“ aktivieren. Dies reduziert den VRAM erheblich, verdoppelt aber fast die Trainingszeit.
Weitere Optionen sind: Schließe alle Programme, trenne deinen 2. Monitor, senke die Bildschirmauflösung, wechsle bei Linux vorübergehend zu einer leichteren Desktop-Umgebung. Sobald das Training gestartet ist, schließe den Browser und überprüfe den Status nur mit der Eingabeaufforderung geöffnet.
Wenn du es nicht lösen kannst, suche im Internet. Wenn du weiterhin Fehler erhältst, gib auf und trainiere in CivitAI.
Trainingsvorschau
Die Ergebnisse werden sich im Laufe der Zeit verbessern, während es lernt.

Trainingsergebnisse
Wenn es fertig ist, sieht das Verzeichnis so aus:
Du kannst anhand der Beispielbilder überprüfen, ob es übertrainiert oder untertrainiert ist. Du wirst es auch sehen, wenn du das LoRA ausführst.
Übertrainiert
Wenn das Modell übertrainiert ist, werden die Bilder „pixelig wie aus Ton gemacht“ sein… Ich weiß nicht, wie ich es beschreiben soll. Die Vorschau-Bilder beginnen zu verzerren.
Sieh dir mit deinen Augen ein generiertes Bild an:

Manchmal erhält man nicht dieses schlechte Ergebnis, aber das Gesicht HÖRT AUF, wie die trainierte Person auszusehen, bis es sich in späteren Epochen verformt.

Die Lösung ist einfach: Teste einfach vorherige Epochen und finde die neueste, die gut funktioniert. Basierend auf dem Beispielbild kannst du leicht das gute finden und die LoRA-Datei, die um die gleiche Zeit generiert wurde.
Es ist SCHWIERIG, EINE AUSZUWÄHLEN!!! Aber es muss getan werden. Teste so viele wie möglich.
Untertrainiert
Wenn es untertrainiert ist (Das Porträtgesicht sieht nicht wie die Person aus und scheint eine Mischung aus einer generischen Person des SD-Modells zu sein, oder das Objekt hat noch nicht die gewünschten Details), kannst du das Training fortsetzen.

In diesem Beispielbild siehst du, dass Details fehlen, wie das Mikrofon, das mit der Krawatte verschmilzt.
Der Unterschied zum Übertraining ist der Mangel an Details.
Wenn du Kohya geschlossen hast, ist das kein Problem, lade einfach die JSON-Datei, die im Ergebnisverzeichnis erstellt wird, und alle verwendeten Konfigurationen werden geladen.
In Parameter > Grundlegend hast du das Feld LoRA-Netzwerkgewichte wo du jede Lora hinzufügen kannst, die du weiter trainieren möchtest.
Benenne die letzte, die du erhalten hast, in einen anderen Namen um, kopiere ihren Speicherort in dieses Feld, ändere die Epochen auf 2 oder 3 (es hängt davon ab, wie viel du weiter trainieren möchtest) und klicke erneut auf Training starten. Es wird das Training fortsetzen.
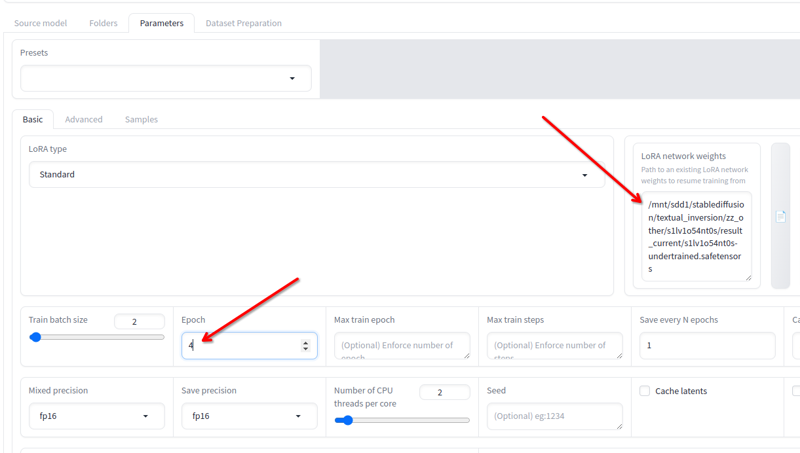
Du kannst das so lange machen, bis es gut ist!
Fertig!
Benenne die endgültige Lora-Epoche, die du möchtest (oder behalte sie, wenn das Endergebnis gut ist), und verwende sie.

Dies ist das Flux-Beispiel:






