
NSFW LoRA 훈련 방법 (FLUX 업데이트)
g
By gerogero
Updated: March 13, 2026
모델 훈련에 사용됨
SD 1.5 리얼리스틱 사진의 경우:
- 훈련: Realistic Vision 5.1
이 모델은 여러 병합에 추가되었으며 다른 거의 모든 리얼리스틱 모델과 잘 작동합니다. v6는 어떤 이유로 잘 작동하지 않습니다. - 생성: Realistic Vision 5.1과 denoise 0.1로 img2img를 사용하여 PicX Real 1.0을 사용합니다. RV만으로도 작업이 가능하지만, 이 조합이 마음에 들었습니다.
SD 1.5 애니메이션의 경우:
- 훈련: AnyLora
이 모델은 훈련에 있어 고전적인 선택입니다. - 생성: Azure Anime v5
SDXL 전체 (여기에는 Pony와 Illustrious 포함):
- 훈련: SDXL Base model
- 생성: Dreamshaper XL Turbo. 저는 7단계를 사용하고, 같은 프롬프트로 새로운 시드를 사용하여 img2img를 수행한 후 결과가 좋습니다!
FLUX 전체:
- 모델: flux1-Dev-Fp8.safetensors (11.1 GB 파일)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 Encoder: t5xxl_fp8_e4m3fn.safetensors
- 16Gb VRAM이 필요합니다. 그러나 이 다른 기사를 시도해 볼 수 있습니다.
제가 사용하는 도구
- 훈련을 위해 설치해야 할 것: Kohya_ss
하지만 때때로 프로세스를 가속화하기 위해 제가 만든 스크립트를 실행합니다. 이 스크립트는 모든 매개변수와 함께 Kohya 스크립트를 호출합니다. 마지막에 이에 대해 이야기할 것입니다.
Flux에 필요한 sd3-flux.1 브랜치입니다. - 생성: InvokeAI
죄송합니다, 저는 여기 Automatic1111과 ComfyUI도 있지만, InvokeAI를 사랑합니다. - Lora 메타데이터 뷰어: https://civitai.com/models/249721
데이터셋 준비
가장 중요한 부분입니다. 훈련할 사람, 객체 또는 원하는 것을 위한 이미지를 수집해야 합니다.
고려해야 할 몇 가지 사항
- 해상도가 낮거나 픽셀이 깨진 이미지는 피하십시오. 업스케일링을 권장하지 않습니다.
- 서로 너무 다른 이미지는 피하십시오. 저는 보통 초상화에 집중합니다.
- 너무 많은 화장, 많은 귀걸이와 목걸이, 이상한 포즈가 있는 이미지는 피하십시오.
- 손. 손이 이상한 위치에 너무 많이 나타나는 이미지는 피하십시오.
- 로고, 다른 사람, 낭비된 공간 등을 제거하여 훈련할 주제만 포함되도록 하나씩 잘라냅니다.
제가 Silvio Santos lora를 위해 수집한 데이터셋을 보여드리겠습니다:

모두 초상화임을 볼 수 있습니다. 다양한 배경과 옷 색상이 필수입니다. 얼굴이 서로 다른 방향을 바라보는 것도 마찬가지입니다.
대칭에 대한 주의 사항
모든 이미지에서 사람의 좌우 측면이 일관된지 확인하십시오. 이는 일반적으로 반전되는 셀카에는 해당되지 않을 수 있습니다.
인간의 얼굴은 대칭적이지 않습니다, 따라서 훈련 중에 혼합된 측면 방향이 있을 경우 결과는 다음과 같을 수 있습니다:

전체 데이터셋의 방향 을 검토하십시오!!
미리보기 이미지가 시간이 지나면서 모두 동일해지기 시작하면, 이는 SD가 양쪽을 학습하려고 시도하고 대칭의 차이로 인해 일부 반전된 이미지에서 손실이 약간 더 높아질 수 있기 때문에 발생할 수 있으며, 학습이 몇 개의 이미지에 갇힐 수 있습니다.
이미지 수
- 5에서 10: 당신의 Lora는 많은 변형이 없을 것이지만, 작동할 수 있습니다.
- 11에서 20: 좋은 지점입니다. 좋은 lora를 생성할 수 있습니다.
- 21에서 50: 이 넓은 범위가 우리가 원하는 것입니다!
- 50에서 100: 너무 많지만 초상화와 전신을 혼합하여 추가할 때 작동합니다.
- > 100: 작업의 낭비입니다.
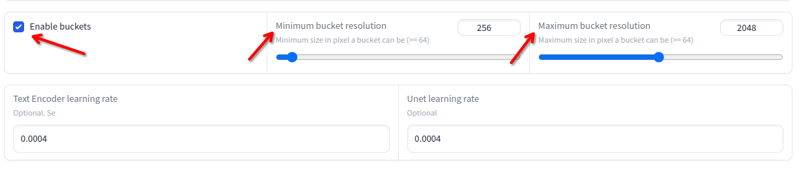
해상도
해상도는 256x에서 2048x까지 다양할 수 있습니다. 이 값보다 낮거나 높은 이미지는 피하십시오. 이 값 내에 있다면 크기를 조정할 필요가 없으며, 훈련이 자동으로 버킷에서 조정합니다:
폴더 구조:
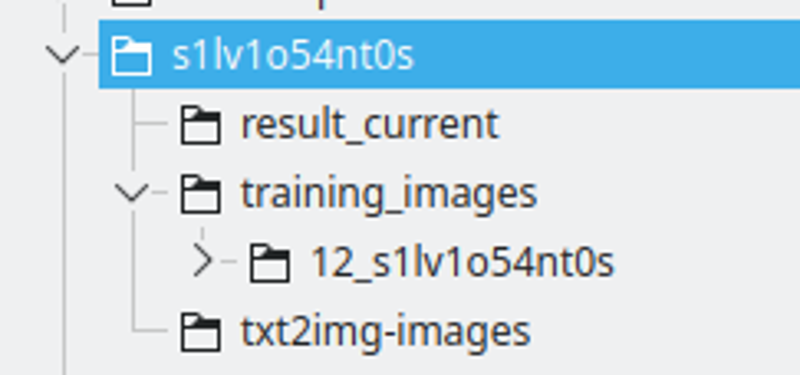
저는 LoRA 문자열 이름으로 폴더를 만듭니다. 문자열의 일부 문자를 숫자로 바꿔서 여러 모델 간에 고유한 토큰이 되도록 합니다.
result_current는 Kohya가 결과를 저장할 위치입니다.
훈련 이미지는 훈련 이미지가 포함된 디렉토리를 가집니다. 이름 규칙 은: 400 / 이미지 수, 언더스코어 및 lora 문자열입니다. 이것은 Kohya가 반복할 횟수가 됩니다. 이 숫자는 에포크 간의 좋은 간격을 유지하는 데 좋은 지점이라고 생각합니다.
txt2img-images는 LoRA를 사용하여 생성된 이미지를 저장하는 곳입니다 - 선택 사항입니다.
캡셔닝
이 과정은 각 이미지가 무엇인지 설명하는 것입니다. 그러면 SD는 노이즈에서 훈련 이미지를 생성하는 데 기존 모델을 사용하는 방법을 알게 됩니다.
Kohya의 유틸리티 탭에서 Blip 캡셔닝을 사용할 수 있습니다. 저는 다음과 같은 설정으로 사용합니다:
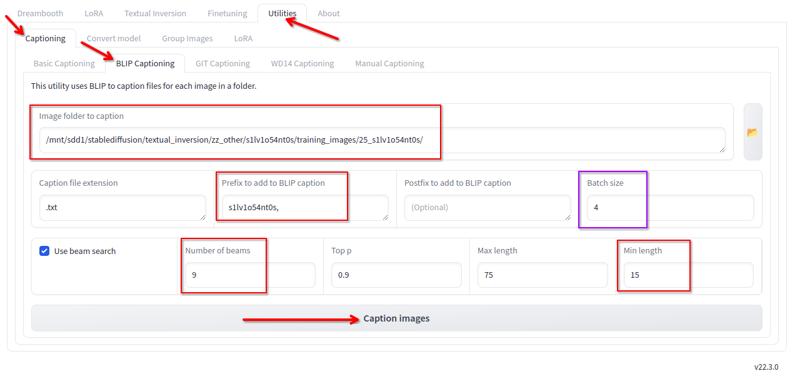
다음과 같이 변경합니다:
- 이미지가 있는 폴더.
- 접두사는 lora 이름과 쉼표입니다.
- 빔 수 9
- 최소 길이 15
- 배치 크기 4
- 나머지 값은 기본값으로 유지합니다.
캡션을 클릭하면, 잠시 후 캡션이 생성됩니다:
이미지가 적으면 캡션을 수정할 수 있습니다. Blip은 "리모컨을 들고 있는" 또는 "손에 마이크를 들고 있는"과 같은 문구를 추가하는 것을 좋아하는데, 이는 사실이 아닙니다. 저는 그냥 무시하고 그렇게 해왔으며, 전체 캡셔닝은 좋습니다.
*이 "기본" 캡셔닝이 Flux에 좋지 않다고 말할 수 있지만, 더 나은 캡셔닝이 LLM을 사용하는 것이 더 좋다고 하지만, 저에게는 잘 작동하고 있습니다.
정규화 폴더
과거에 제가 발표한 첫 번째 lora에 대해 4K 이상의 여성 이미지가 포함된 정규화 폴더를 사용했습니다. 이제는 사용하지 않습니다 데이터셋이 캡셔닝되지 않고 더 다양할 때만 필요하기 때문입니다.
사용하면 시간과 단계가 두 배로 늘어납니다.
사용하지 마십시오.
훈련 실행
여기서 훈련을 실행합니다. SD1.5의 경우 이러한 설정은 8GB VRAM이 필요하고, SDXL은 10GB VRAM이 필요하며, Flux는 16GB VRAM이 필요합니다.
Kohya 설치는 이 가이드의 범위를 벗어납니다.
Kohya 설정
SD1.5 설정: https://jsonformatter.org/a3213d
SDXL 설정: https://jsonformatter.org/66e5c8
FLUX 설정: https://jsonformatter.org/45c1fc
* 링크가 만료되면 알려주세요
* FLUX의 경우, 훈련을 1800단계로 제한하고 있습니다 (위의 설정 파일에 이미 포함되어 있음) 하지만 약 1200 단계에서 LoRA가 이미 좋습니다.
* 또한 FLUX의 경우, 위의 설정이 ANIMES와 CARTOONS에 대한 훈련을 수렴하지 않았습니다. 따라서, -learning_rate=0.0004 -unet_lr=0.0004를 0.001 또는 0.002로 증가시켜야 할 수 있습니다. 그렇게 하면 훈련이 더 적은 단계에서 잘 진행되지만, 과적합이 더 쉬울 수 있습니다.
이 파일들을 Kohya LORA 탭 — 꿈부트 탭이 아님 —에 로드하십시오. 구성 파일을 클릭하고 로드하십시오.
변경해야 할 설정:
모델 및 폴더 섹션:
- 이미지 폴더 – 우리가 이전에 만든 training_images 폴더입니다. 숫자가 있는 폴더가 아니라 부모 폴더입니다.
- 출력 폴더 – 우리가 이전에 만든 result_current 폴더입니다.
- 출력 이름 – lora의 문자열 이름입니다.
매개변수 탭 > 고급 > 샘플:
- 프롬프트를 변경하십시오. 간단해야 하며, 샘플 이미지를 생성하는 데 사용됩니다. 간단하게 유지하십시오.
매개변수 탭 > 기본:
- 에포크 수를 변경할 수 있지만, 시작할 때는 6을 유지하는 것이 좋습니다.
각 필드의 의미에 대해 인터넷에서 검색하십시오. 지금 모든 것을 설명하는 것은 범위를 벗어나지만, 여기에서 읽을 수 있습니다: LoRA 훈련 매개변수
하드웨어 활용
대부분의 설정은 하드웨어 요구 사항을 변경합니다.
이들은 RTX2060 슈퍼 12GB VRAM을 사용하여 저에게 효과가 있었던 설정입니다 — FLUX의 경우 RTX 4060 TI 16GB VRAM으로 업그레이드했습니다.
예를 들어, 제 RTX2060은 3060과 같은 bf16을 지원하지 않으므로 fp16을 사용합니다. 이렇게 하면 메모리를 절약할 수 있지만, 12GB로 잘 작동했습니다.
모든 것을 변경한 후, "훈련 시작"을 클릭하십시오. 콘솔에서 다음과 같은 내용을 볼 수 있습니다:
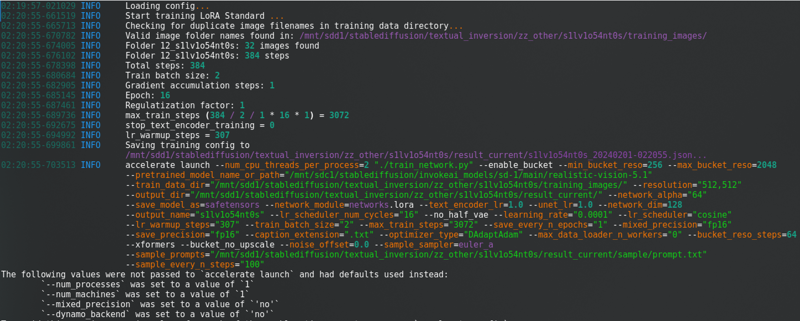
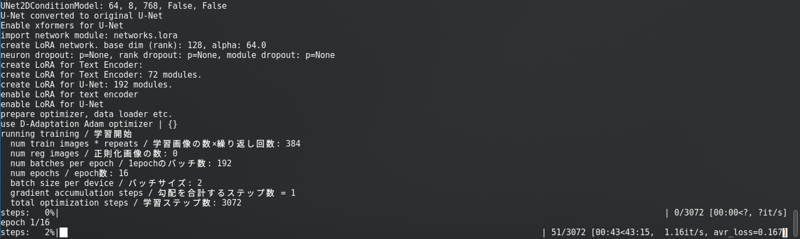
긴 진행 표시줄과 함께.
SD1.5: 저는 잠금을 디스크에 캐시하지 않습니다. 더 빠르지만 SDXL과 거의 동일한 VRAM을 사용합니다.
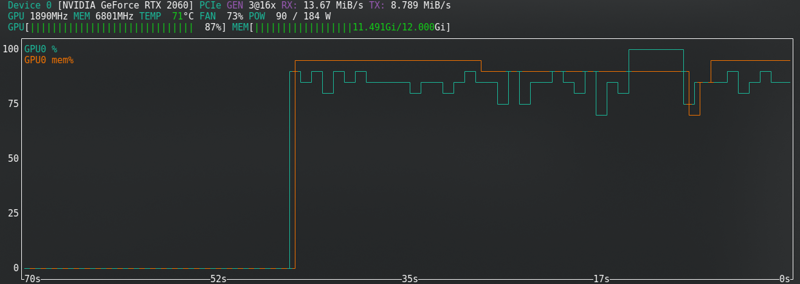

SDXL:
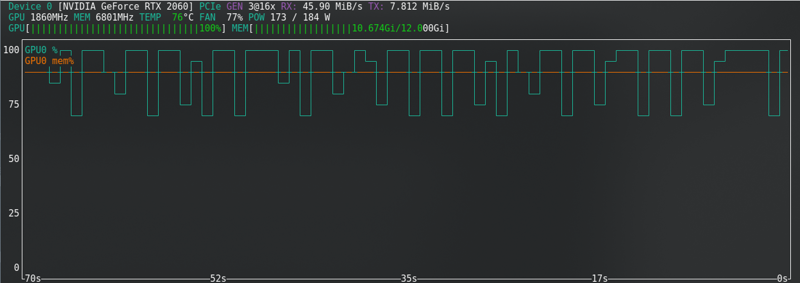

FLUX: 새 카드로도 한계에 가까움!!!!!
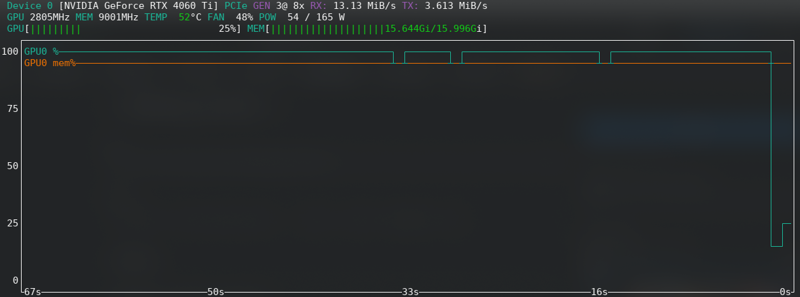
메모리 부족 오류
CUDA 메모리 부족 오류가 발생하면, 한계에 도달한 것입니다. 디스크에 잠금을 캐시하도록 활성화하고, 하드웨어가 지원하는 경우 fp16에서 bf16으로 변경하고, 배치 크기를 2에서 1로 줄이십시오.
Flux의 경우 "분할 모드"를 활성화할 수 있습니다. 이렇게 하면 VRAM이 많이 줄어들지만 훈련 시간이 거의 두 배가 됩니다.
다른 옵션은: 모든 프로그램을 닫고, 두 번째 모니터를 분리하고, 디스플레이 해상도를 낮추고, 리눅스에서는 가벼운 데스크탑 환경으로 임시로 변경하고, 훈련을 시작한 후에는 브라우저를 닫고 명령 프롬프트만 열어 상태를 확인하십시오.
해결할 수 없다면, 인터넷에서 검색하십시오. 여전히 오류가 발생하면 포기하고 CivitAI에서 훈련하십시오.
훈련 미리보기
매 100단계(변경 가능)마다 훈련은 results_current/sample 폴더에 샘플 이미지를 생성합니다. 그러면 작동하는지 여부를 알 수 있습니다.
결과는 시간이 지남에 따라 개선됩니다.

훈련 결과
훈련이 끝나면 디렉토리는 다음과 같이 보일 것입니다:
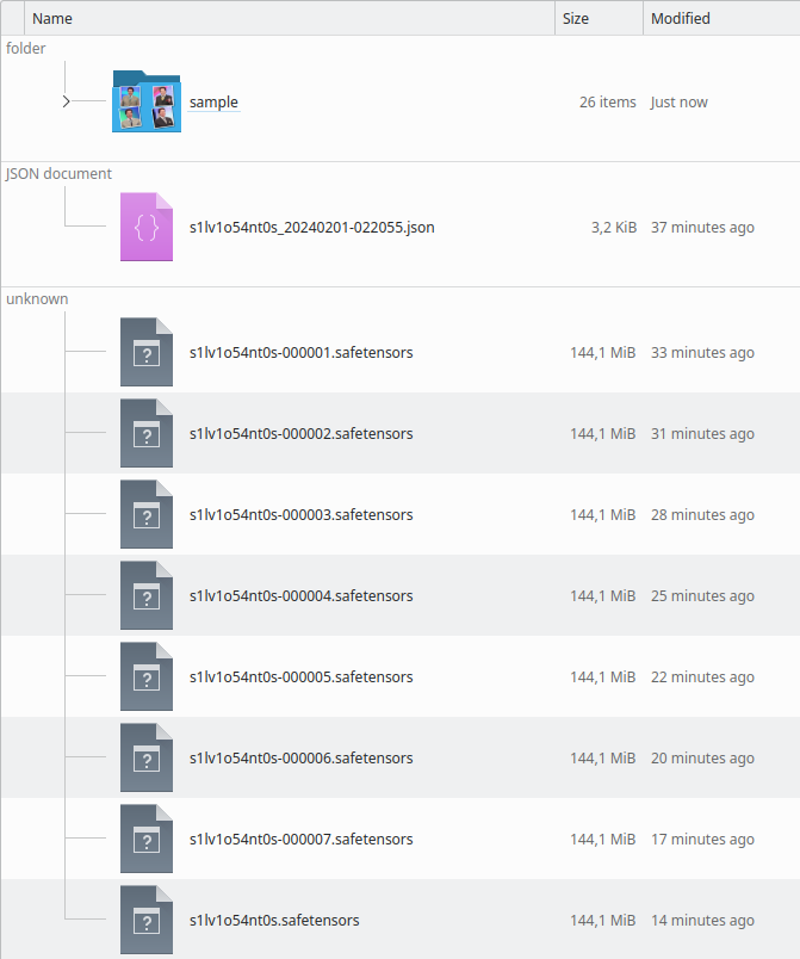
샘플 이미지를 통해 과훈련되었는지 과소훈련되었는지 확인할 수 있습니다. LoRA를 실행할 때도 이를 확인할 수 있습니다.
과훈련
모델이 과훈련되면 이미지는 "점토로 만들어진 픽셀화된" 모습이 됩니다... 어떻게 설명해야 할지 모르겠습니다. 미리보기 이미지가 왜곡되기 시작합니다.
눈으로 확인하십시오, 생성된 이미지:

가끔 이렇게 나쁜 결과가 나오지 않지만, 얼굴이 훈련된 사람처럼 보이지 않다가 나중의 에포크에서 변형됩니다.

해결책은 간단합니다: 이전 에포크를 테스트하고 잘 작동하는 가장 최근의 것을 확인하십시오. 샘플 이미지를 기반으로 쉽게 좋은 것을 찾고, 같은 시기에 생성된 LoRA 파일을 찾을 수 있습니다.
하나를 선택하는 것은 어렵습니다!!! 하지만 해야 합니다. 가능한 한 많이 테스트하십시오.
과소훈련
과소훈련된 경우(초상화 얼굴이 사람처럼 보이지 않고 SD 모델의 일반적인 사람의 조합처럼 보이거나, 객체에 원하는 세부 사항이 없는 경우) 훈련을 재개할 수 있습니다.

이 예제 이미지에서는 마이크가 넥타이와 합쳐지는 것과 같은 세부 사항이 누락되어 있습니다.
과훈련과의 차이는 세부 사항의 부족입니다.
Kohya를 닫았다면, 문제 없습니다. 결과 디렉토리에서 생성된 json을 로드하면 사용된 모든 설정이 로드됩니다.
매개변수 > 기본에서, 훈련을 계속할 수 있는 LoRA 네트워크 가중치 필드가 있습니다.
가장 최근의 것을 다른 이름으로 바꾸고, 이 필드에 위치를 복사한 후, 에포크를 2 또는 3으로 변경하고(훈련을 계속하는 데 얼마나 필요한지에 따라 다름) 다시 훈련 시작 을 클릭하십시오. 훈련이 재개됩니다.
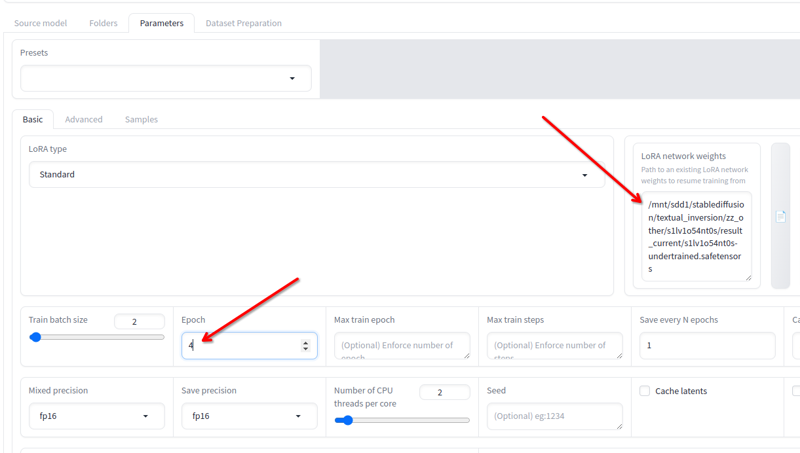
좋아질 때까지 계속할 수 있습니다!
완료!
원하는 최종 lora 에포크의 이름을 바꾸거나(또는 최종 결과가 좋다면 유지) 사용하십시오.
이것은 SD1.5 예제:

이것은 Flux 예제:






