
Como treinar LoRA NSFW (atualizado com FLUX)
g
By gerogero
Updated: March 13, 2026
Modelos usados para treinamento
Para SD 1.5 fotos realistas:
- Treinamento: Realistic Vision 5.1
Este foi adicionado nas mesclagens de maio e também faz parte de uma mesclagem. Funciona bem com quase todos os outros modelos realistas. A v6, por algum motivo, não funciona bem da mesma forma. - Geração: Realistic Vision 5.1, e um img2img com um denoise de 0.1 usando PicX Real 1.0. RV sozinho faz o trabalho, mas eu gostei dessa combinação.
Para SD 1.5 Anime:
- Treinamento: AnyLora
Este é um clássico para treinamento. - Geração: Azure Anime v5
Para SDXL geral (inclua Pony e Illustrious aqui):
- Treinamento: Modelo Base SDXL
- Geração: Dreamshaper XL Turbo. Eu uso 7 passos, e depois faço um img2img com o mesmo prompt, mas uma nova seed, então o resultado é bom!
Para FLUX geral:
- Modelo: flux1-Dev-Fp8.safetensors (arquivo de 11.1 GB)
- VAE: ae.safetensors
- Clip: clip_l.safetensors
- T5 Encoder: t5xxl_fp8_e4m3fn.safetensors
- 16Gb Vram necessário. Mas você pode tentar este outro artigo aqui.
Ferramentas que eu uso
- Para treinamento você precisará instalar: Kohya_ss
Mas às vezes eu apenas executo um script que fiz para acelerar o processo, ele chama os scripts do Kohya com todos os parâmetros. Eu falarei sobre isso no final.
A branch sd3-flux.1 é necessária para o Flux. - Geração: InvokeAI
Desculpe pessoal, eu tenho Automatic1111 e ComfyUI aqui, mas eu amo o InvokeAI. - Visualizador de Metadados Lora: https://civitai.com/models/249721
Preparação do conjunto de dados
Esta é a parte mais importante. Você precisa coletar imagens da pessoa, objeto ou qualquer coisa que você queira treinar.
Há algumas coisas a considerar
- Evite imagens de baixa resolução ou pixeladas. Eu não recomendo aumentar a escala.
- Evite imagens muito diferentes umas das outras. Eu geralmente me concentro em retratos.
- Evite imagens com muito maquiagem, muitos brincos e colares, poses estranhas.
- MÃOS. Evite imagens onde as mãos aparecem demais em posições estranhas.
- Eu recorto uma a uma para garantir que incluam apenas o sujeito a ser treinado, removendo logotipos, outras pessoas, espaços desperdiçados, etc.
Deixe-me mostrar o conjunto de dados que eu obtive para Silvio Santos lora:

Você pode ver que são todos retratos. Diferentes fundos e cores de roupas são essenciais. Rostos olhando para diferentes lados também.
Nota sobre simetria
Verifique se todos os lados direito e esquerdo da pessoa nas imagens são consistentes. Isso pode não ser o caso com selfies que geralmente estão invertidas.
O rosto humano não é simétrico, então se você tiver uma orientação lateral mista durante seu treinamento, o resultado pode ser assim:

Por favor, revise a orientação de todo o seu conjunto de dados!!
Se as imagens de pré-visualização, após um tempo, começarem a ser todas iguais, esse pode ser o motivo, já que o SD tentará aprender ambos os lados e a diferença na simetria pode causar uma perda um pouco maior em algumas imagens invertidas, então o aprendizado ficará preso em algumas poucas imagens.
Número de imagens
- 5 a 10: Seu Lora não terá muitas variações, mas pode funcionar
- 11 a 20: Bom ponto. Pode gerar um bom lora.
- 21 a 50: Essa ampla faixa é o que queremos!
- 50 a 100: Muito, mas funciona quando você quer adicionar retratos E corpo inteiro misturados.
- > 100: Desperdício de trabalho.
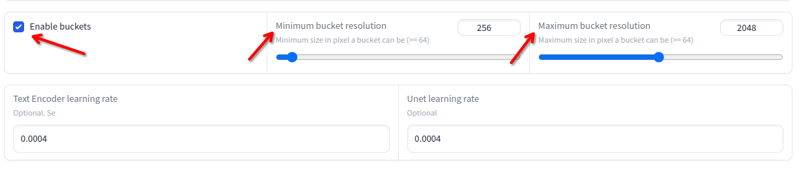
Resolução
A resolução pode variar de 256x a 2048x. Evite imagens abaixo ou acima desses valores. Você não precisa redimensionar se estiver dentro desses valores, pois o treinamento fará isso automaticamente em buckets:
A estrutura da pasta:
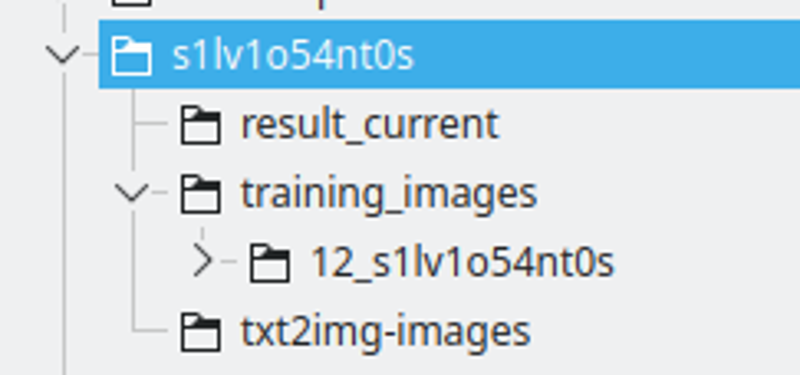
Eu crio uma pasta com o nome da string LoRA. Nomeio a string substituindo algumas letras por números, para garantir que será um token único entre muitos modelos.
O result_current será o lugar onde o Kohya salvará os resultados
As imagens de treinamento terão o diretório contendo as imagens de treinamento. A convenção de nomenclatura é: 400 / número de imagens, um sublinhado e a string lora. Este será o número de repetições que o Kohya fará. Eu acho esse número um bom ponto para ter um bom intervalo entre épocas.
txt2img-images é onde eu armazeno imagens geradas usando a LoRA – Opcional.
Legendas
Este é o processo onde você descreverá o que cada imagem é, então o SD saberá como usar o modelo existente para construir as imagens de treinamento a partir do ruído.
No Kohya, na aba de utilitários, temos a legenda Blip. Eu uso isso com essas configurações:
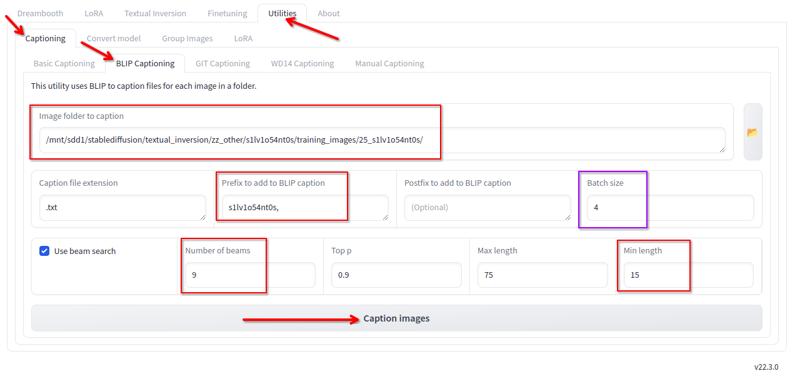
Eu mudo o seguinte:
- Pasta onde estão as imagens.
- Prefixo é o nome da lora e uma vírgula
- Número de feixes 9
- Comprimento mínimo 15
- Tamanho do lote 4
- Todos os outros valores eu mantenho como padrão.
Clique em legenda e, após um tempo, ele gerará as legendas:
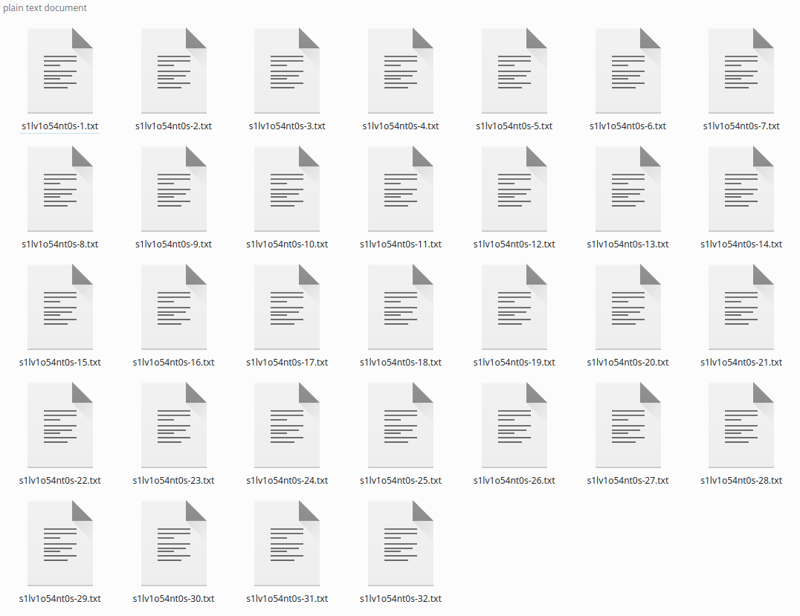
Se você tiver poucas imagens, pode corrigir as legendas, já que o Blip ADORA adicionar frases como “segurando um controle remoto” ou “Com um microfone na mão” que não são verdadeiras. Eu apenas ignoro e tem funcionado assim, já que a legenda geral é boa.
*Você pode dizer que essa legenda “básica” não é boa para Flux, que uma legenda melhor usando LLM é melhor, mas tem funcionado bem para mim.
Pasta de regularização
No passado, para os primeiros loras que publiquei, usei uma pasta de regularização com mais de 4 mil imagens de mulheres. Eu parei de usá-la pois só é necessária quando seu conjunto de dados não está legendado e é mais variado.
Usá-la dobrará o tempo e os passos necessários.
Não use.
Executando o treinamento
Aqui vamos executar o treinamento. Para SD1.5 essas configurações requerem 8GB de Vram, SDXL requer 10GB de Vram, Flux requer 16GB de Vram.
Instalar o Kohya está além do escopo deste guia.
Configurações do Kohya
Configs SD1.5: https://jsonformatter.org/a3213d
Configs SDXL: https://jsonformatter.org/66e5c8
Configs FLUX: https://jsonformatter.org/45c1fc
* Deixe-me saber se os links expirarem
* Para FLUX, estou limitando o treinamento a 1800 passos (já no arquivo de configuração acima), mas em torno de 1200 passos a LoRA já está boa.
* Também para FLUX, minhas configurações acima não estavam convergindo o treinamento para ANIMES e CARTOONS. Então, você pode ter que aumentar o –learning_rate=0.0004 –unet_lr=0.0004 para 0.001 ou 0.002. Com isso, o treinamento se torna bom em menos passos, mas pode superajustar mais facilmente.
Carregue esses arquivos na aba LORA do Kohya — NÃO NA ABA DREAMBOOT — clique no arquivo de configuração e carregue-o.
Configs que você TEM QUE mudar:
Seção Modelo e Pastas:
- Pasta de imagens – a pasta training_images que criamos antes. NÃO a pasta com o número, a pasta pai.
- Pasta de saída – a pasta result_current que criamos antes
- Nomenclatura de saída – o nome da string da lora
Aba de Parâmetros > Avançado > Amostras:
- Mude o prompt. Ele deve ser simples, será usado para gerar as imagens de amostra. Mantenha simples
Aba de Parâmetros > Básico:
- Você pode mudar o número de épocas, mas eu manteria 6 para começar.
Pesquise na internet sobre o que cada campo significa, está fora do escopo explicar todos agora, mas você pode ler aqui: Parâmetros de treinamento LoRA
Utilização de hardware
A maioria das configurações muda os requisitos de hardware.
Essas são as que funcionaram para mim, usando uma RTX2060 super com 12GB de Vram — Para FLUX eu atualizei para uma RTX 4060 TI 16GB de Vram.
Por exemplo, minha RTX2060 não suporta bf16 como as 3060s, então eu uso fp16. Isso economizaria memória, mas é o que é e com 12G tem funcionado.
Após mudar tudo isso, clique em “Iniciar treinamento“. Você verá isso no console:
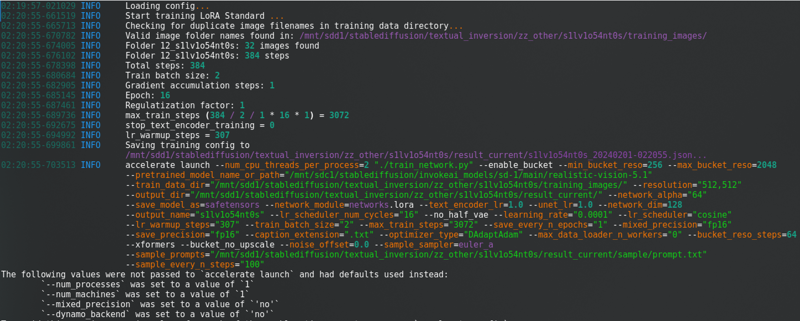
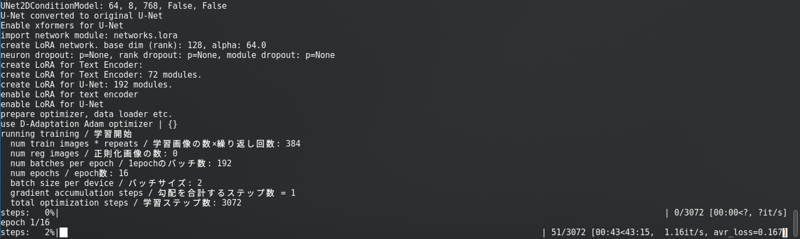
Com uma barra de progresso longa.
SD1.5: Eu não armazeno latentes no disco. É mais rápido, mas usa quase a mesma Vram que o SDXL.
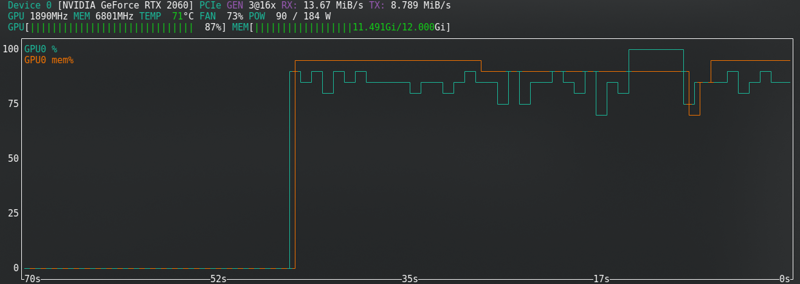

SDXL:
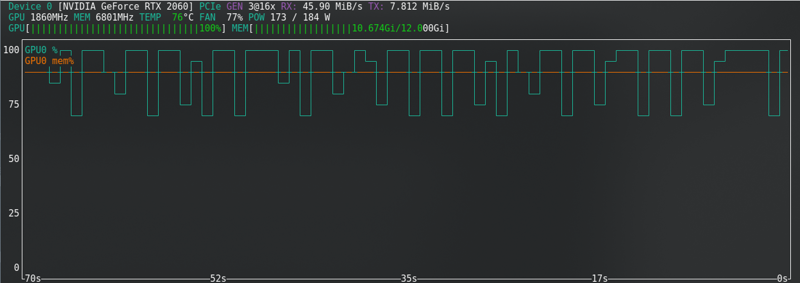

FLUX: Perto do limite mesmo com a nova placa!!!!!
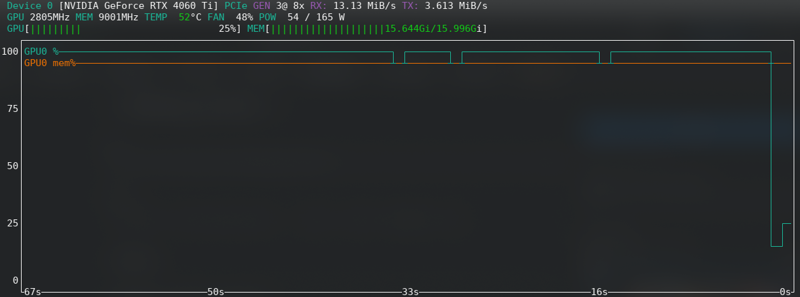
Erro de falta de memória
Se você receber erros de CUDA fora de memória, então você está no limite. Ative o cache de latentes no disco, mude de fp16 para bf16 se seu hardware suportar, reduza o tamanho do lote de 2 para 1.
Para o Flux, você pode ativar o “Modo de divisão”. Isso reduz muito a VRAM, mas quase dobra o tempo de treinamento.
Outras opções são: Fechar todos os programas, desconectar seu segundo monitor, diminuir a resolução da tela, se estiver no Linux mudar temporariamente para um ambiente de desktop mais leve, uma vez que o treinamento for acionado, feche o navegador e verifique o status apenas com o prompt de comando aberto.
Se você não conseguir resolver, pesquise na internet. Se ainda estiver recebendo erros, então desista e treine no CivitAI.
Pré-visualização do treinamento
A cada 100 passos (você pode mudar isso) o treinamento criará uma imagem de amostra na pasta results_current/sample, então você pode ter uma ideia se está funcionando ou não.
Os resultados melhorarão com o tempo à medida que está aprendendo.

Resultados do treinamento
Quando terminar, o diretório ficará assim:
Você pode verificar pelas imagens de amostra se está supertreinado ou subtreinado. Você verá isso ao executar a LoRA também.
Supertreinado
Se o modelo estiver supertreinado, as imagens ficarão “pixeladas como se fossem feitas de argila”… Eu não sei como descrever. As imagens de pré-visualização começarão a distorcer.
Veja com seus olhos, uma imagem gerada:

Às vezes não chega a esse resultado ruim, mas o rosto PARA de parecer com a pessoa treinada até que se deforme em épocas posteriores.

A solução é simples: Basta testar épocas anteriores e ver a mais recente que funciona bem. Com base na imagem de amostra, você pode facilmente encontrar a boa e localizar o arquivo LoRA gerado por volta da mesma época.
É DIFÍCIL ESCOLHER UMA!!! Mas deve ser feito. Teste o máximo que puder.
Subtreinado
Se estiver subtreinado (o rosto do retrato não se parece com a pessoa e parece uma mistura de pessoa genérica do modelo SD, ou o objeto não tem os detalhes desejados ainda) você pode retomar o treinamento.

Nesta imagem de exemplo, você vê que detalhes estão faltando, como o microfone se fundindo com a gravata.
A diferença em relação ao supertreinamento é a falta de detalhes.
Se você fechou o Kohya, sem problemas, basta carregar o json que ele cria no diretório de resultados e todas as configurações usadas serão carregadas.
Em Parâmetros > Básico, você tem o campo Pesos da rede LoRA onde pode adicionar qualquer lora que deseja continuar treinando.
Renomeie a última que você obteve para qualquer outro nome, copie sua localização para este campo, mude as épocas para 2 ou 3 (depende de quanto você precisará continuar treinando) e clique em iniciar treinamento novamente. Isso retomará o treinamento.
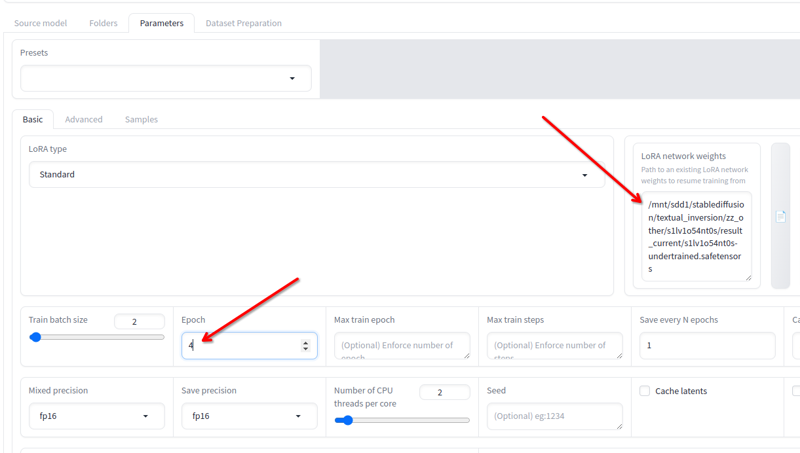
Você pode fazer isso até que fique bom!
Concluído!
Renomeie a última época lora que você deseja (ou mantenha se o resultado final estiver bom) e use-a.
Este é o exemplo SD1.5:

Este é o exemplo Flux:






